# AI セキュリティ概要
### Introduction
#### Table of contents
> Category: discussion\
> Permalink:
* [AI Security Overview](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/docs/ai_security_overview/README.md)\
\- [About the AI Exchange](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/about/README.md)\
\- [Roadmap](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/roadmap/README.md)\
\- [How to use this document](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/document/README.md)\
\- [Organize AI](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/organize/README.md)\
\- [Essentials](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/essentials/README.md)\
\- [Threats](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/threatsoverview/README.md)\
[Highlight: Threat matrix](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/aisecuritymatrix/README.md)\
[Highlight: Agentic AI perspective](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/agenticaithreats/README.md)\
[Highlight: Navigator](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/navigator/README.md)\
\- [Controls](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/controlsoverview/README.md)\
[Highlight: Periodic table of threats and controls](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/periodictable/README.md)\
\- [Risk analysis](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/riskanalysis/README.md)\
[Highlight: Threat modeling](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/threatmodel/README.md)\
\- [How about ...](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/docs/ai_security_overview/README.md#how-about-)
* [Deep dive into threats and controls:](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/navigator/README.md)\
\- [1. General controls](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/docs/1_general_controls/README.md)\
[1.1 Governance controls](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/governancecontrols/README.md)\
[1.2 Data limitation](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/datalimit/README.md)\
[1.3 Limit unwanted behaviour](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/limitunwanted/README.md)\
\- [2. Input threats and controls](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/docs/2_threats_through_use/README.md)\
[Highlight: Prompt injection protection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/promptinjectionsevenlayers/README.md)\
\- [3. Development-time threats and controls](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/docs/3_development_time_threats/README.md)\
\- [4. Runtime conventional security threats and controls](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/docs/4_runtime_application_security_threats/README.md)
* [AI security testing](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/docs/5_testing/README.md)
* [AI privacy](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/aiprivacy/README.md)
* [References](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/docs/ai_security_references/README.md)
* [Index](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/docs/ai_security_index/README.md)
#### AI Exchange について
> カテゴリ: ディスカッション\
> パーマリンク:
If you want to jump right into the content, head on to the [Table of contents](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/toc/README.md) or [How to use this document](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/document/README.md).
**Summary**\
Welcome to the go-to comprehensive resource for AI security & privacy - over 300 pages of practical advice and references on protecting AI, and data-centric systems from threats - where AI consists of ALL AI: Analytical AI, Discriminative AI, Generative AI and heuristic systems. This content serves as key bookmark for practitioners, and is contributed actively and substantially to international standards such as ISO/IEC and the AI Act through official standard partnerships. Through broad collaboration with key institutes and SDOs, the *Exchange* represents the consensus on AI security and privacy.
[](https://youtu.be/kQC7ouDB_z8)
**Details**\
The OWASP AI Exchange has open sourced the global discussion on the security and privacy of AI and data-centric systems. It is an open collaborative OWASP Flagship project to advance the development of AI security & privacy standards, by providing a comprehensive framework of AI threats, controls, and related best practices. Through a unique official liaison partnership, this content is feeding into standards for the EU AI Act (70 pages contributed), ISO/IEC 27090 (AI security, 70 pages contributed), ISO/IEC 27091 (AI privacy), and [OpenCRE](https://opencre.org) - which links AI Exchange with many of the AI security standards and guidelines - and makes it accessible through the security chatbot [OpenCRE-Chat](https://opencre.org/chatbot).
データ中心のシステムは、AI システムと、AI Exchange の脅威とコントロール (データポイズニング、データサプライチェーンマネジメント、データパイプラインセキュリティなど) の多くに関連する AI モデルを持たない「ビッグデータ」システム (データウェアハウス、BI、レポーティング、ビッグデータなど) に分けられます。
Security here means preventing unauthorized access, use, disclosure, disruption, modification, or destruction. Modification includes manipulating the behaviour of an AI model in unwanted ways.
Our **mission** is to be the global go-to resource for security and privacy practitioners working with AI and data-centric systems—bringing alignment and encouraging collaboration across initiatives. In doing so, we create a safe, open, and independent space where everyone can find and share insights. Follow [AI Exchange at LinkedIn](https://www.linkedin.com/company/owasp-ai-exchange/).
**How it works**\
The AI Exchange is displayed here at [owaspai.org](https://owaspai.org) and edited using a [GitHub repository](https://github.com/OWASP/www-project-ai-security-and-privacy-guide/tree/main/content/ai_exchange/content) (see the links *Edit on Github*). It is an **open-source living publication** for the worldwide exchange of AI security & privacy expertise. It is structured as one coherent resource consisting of several sections under 'content', each represented by a page on this website.
This material is evolving constantly through open source continuous delivery. The authors group consists of over 70 carefully selected experts (researchers, practitioners, vendors, data scientists, etc.) and other people in the community are welcome to provide input too. See the [contribute page](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/contribute/README.md).
AI セキュリティコミュニティ による [OWASP AI Exchange](https://owaspai.org) には [CC0 1.0](http://creativecommons.org/publicdomain/zero/1.0?ref=chooser-v1) のマークが付けられており、著作権や帰属を明示することなく、どの部分でも自由に利用できることを意味します。可能であれば、読者がより多くの情報を見つけられるように、OWASP AI Exchange のクレジットやリンクを記載していただけると幸いです。
**Who is this for**\
The Exchange is for practitioners in security, privacy, engineering, testing, governance, and for end users in an organization - anyone interested in the security and privacy of AI systems. The goal is to make the material as easy as possible to access. Using the [Risk analysis section](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/riskanalysis/README.md) you can quickly narrow down the issues that matter to your situation, whether you are a large equipment manufacturer designing an AI medical device, or a small travel agency using a chatbot for HR purposes.
**History**\
AI Exchange は [Rob van der Veer](https://www.linkedin.com/in/robvanderveer/) によって 2022 年に設立されました。セキュリティ標準の橋渡し役、[Software Improvement Group](https://www.softwareimprovementgroup.com) の最高 AI 責任者、AI とセキュリティで 33 年の経験を持ち、AI ライフサイクルに関する ISO/IEC 5338 の主執筆者、OpenCRE の創設者であり、現在は CEN/CENELEC で ISO/IEC 27090、ISO/IEC 27091、EU AI 法に関するセキュリティ要件に取り組んでおり、EU 加盟国によって共同編集者に選出されました。
The project started out as the 'AI security and privacy guide' on October 22 and was rebranded a year later as 'AI Exchange' to highlight the element of global collaboration. In March 2025 the AI Exchange was awarded the status of 'OWASP Flagship project' because of its critical importance, together with the ['GenAI Security Project'](https://genai.owasp.org/).
**The AI Exchange is trusted by industry giants**
Dimitri van Zantvliet, Director Cybersecurity, Dutch Railways:
> "A risk-based, context-aware approach—like the one OWASP Exchange champions—not only supports the responsible use of AI, but ensures that real threats are mitigated without burdening engineers with irrelevant checklists. We need standards written by those who build and defend these systems every day."
Sri Manda, Chief Security & Trust Officer at Peloton Interactive:
> “AI regulation is critical for protecting safety and security, and for creating a level playing field for vendors. The challenge is to remove legal uncertainty by making standards really clear, and to avoid unnecessary requirements by building in flexible compliance. I’m very happy to see that OWASP Exchange has taken on these challenges by bringing the security community to the table to ensure we get standards that work.”
Prateek Kalasannavar, Staff AI Security Engineer, Lenovo:
> “At Lenovo, we’re operationalizing AI product security at scale, from embedded inference on devices to large-scale cloud-hosted models. OWASP AI Exchange serves as a vital anchor for mapping evolving attack surfaces, codifying AI-specific testing methodologies, and driving community-aligned standards for AI risk mitigation. It bridges the gap between theory and engineering.”
**Mission/vision**
The mission of the AI Exchange is to enable people to find and use information to ensure that AI systems are secure and privacy preserving.
The vision of the AI Exchange is that the main challenge for people is to find the right information and then understand it so it can be turned into action. One of the underlying issues is the complexity, inconsistency, fragmentation and incompleteness of the standards and guideline landscape - with issues of quality and being outdated - caused by the general lack of expertise in AI security in the industry. What resource to use?
The AI Exchange achieves:
* AUTHORITATIVE - active alignment with other resources through careful analysis and through close collaboration - particularly through substantial contribution to leading international standards at ISO/IEC and the AI Act - making sure the AI Exchange represents consensus.
* OPEN - Anybody that wants to, can contribute to the AI Exchange body of knowledge, with strong quality assurance, including a screening process for Authors.
* FREE - Anybody that wants to, use can use it in any way. Free of copyright and attribution.
* COVERAGE - comprehensive guidance instead of a selected set of issues (like a top 10 which is more for awareness) - and about all AI and data-intensive systems. AI is much more than Generative AI.
* UNIFIED - a coherent resource instead of a fragmented set of disconnected separate resources.
* CLEAR - clear explanation, including also the why and how and not just the what.
* LINKED - referring to various other sources instead of complex text that incorrectly suggests it is complete. This makes the Exchange the place to start
* EVOLVING - continuous updates instead of occasional publications.
All aspects above make the Exchange the go-to resource for practitioners, users, and training institutes - effectively and informally making the AI Exchange the standard in AI security.
NOTE: Producing and continuously updating a comprehensive and coherent quality resource requires a strong coordinated approach. It is much harder than an approach of every person for themselves. But necessary.
#### 関連する OWASP AI イニシアチブ
> カテゴリ: ディスカッション\
> パーマリンク:
[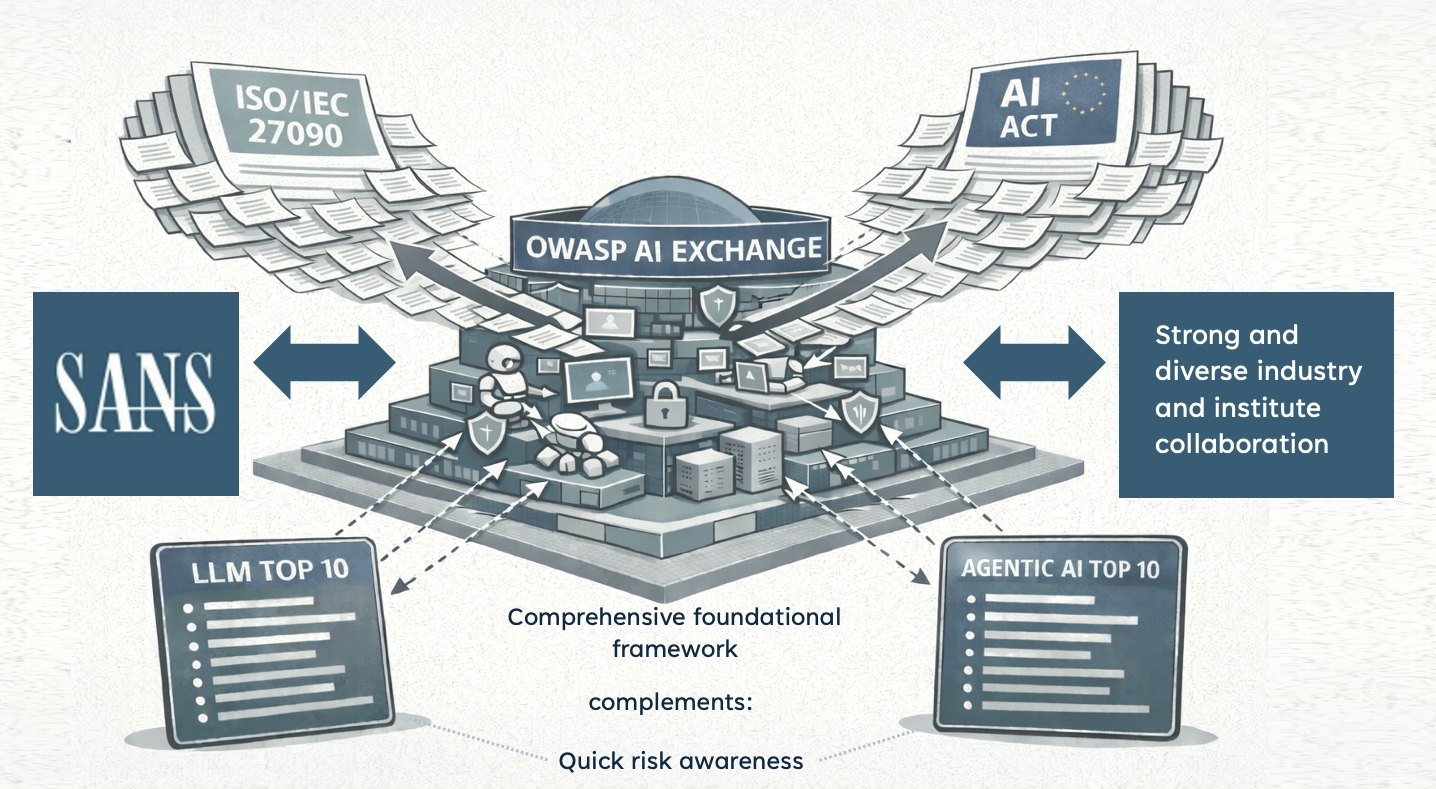](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/refs/heads/main/content/ai_exchange/static/images/aixpositioning.png)
In short:
* The **OWASP AI Exchange** is a comprehensive core framework of the AI security fundamentals: threats, controls and related best practices for all AI, actively aligned with international standards and feeding into them. It covers all types of AI, and next to security it discusses privacy as well.
* The **OWASP GenAI Security Project** is a growing collection of documents on the security of Generative AI, covering a wide range of topics including the LLM top 10.
Here's more information on AI at OWASP:
* If you want to **understand how to ensure security or privacy of your AI or data-centric system** (GenAI or not), or want to align with AI security standards, you can use the [AI Exchange](https://owaspai.org), and from there you will be referred to relevant further material (including GenAI security project material) where necessary.
* If you want to achieve **quick awareness** of the top security concerns for Large Language Models, check out the [LLM top 10 of the GenAI project](https://genai.owasp.org/llm-top-10/). Please know that it is not complete, intentionally - for example it does not include the security of prompts.
Some more details on projects:
* [The OWASP AI Exchange(this work)](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/about/README.md) is the go-to single resource for AI security & privacy - over 300 pages of practical advice and references on protecting AI, and data-centric systems from threats - where AI consists of Analytical AI, Discriminative AI, Generative AI and heuristic systems. This content serves as a key bookmark for practitioners, and is contributed actively and substantially to international standards such as ISO/IEC and the AI Act through official standard partnerships.
* The [OWASP GenAI Security Project](https://genai.owasp.org/) is an umbrella project of various initiatives that publish documents on Generative AI security, including the LLM AI Security & Governance Checklist and the LLM top 10 - featuring the most severe security risks of Large Language Models.
* [OpenCRE.org](https://opencre.org) has been established under the OWASP Integration standards project(from the *Project wayfinder*) and holds a catalog of common requirements across various security standards inside and outside of OWASP. OpenCRE links all AI security controls and threats across standards and guidelines, and the Exchange features a mechanism to insert the correct references for all sections to owaspai.org. This effectively makes the Exchange a hub for the AI security standards landscape. More details in [this LinkedIn post](https://www.linkedin.com/posts/robvanderveer_announcing-the-rosetta-stone-of-ai-security-share-7454426279262564352-SLzR).
* Further AI projects at OWASP can be found [here](https://owasp.org/search/?searchString=AI)
What makes the Exchange special is FOUNDATION:
* F – Fundamentals: comprehensive threat & control model
* O – One integrated body of knowledge (as opposed to a collection of documents)
* U – Universal: covers all AI & data-centric systems
* N – No copyright restrictions (fully shareable)
* D – Data & privacy included
* A – Aligned with international standards
* T – Technically grounded (engineering-oriented)
* I – Iteratively updated (continuous instead of yearly)
* O – Open (any expert can contribute)
* N – Networked - bridge between standards, researchers, and practitioners
The AI Exchange has strong and diverse collaboration with industry and institutes, for example a formal ongoing collaboration with SANS Institute to share expertise and support broad education.
#### AI Exchange roadmap
> Category: discussion\
> Permalink:
Our **mission** is to be the global go-to resource for security and privacy practitioners working with AI and data-centric systems—bringing alignment and encouraging collaboration across initiatives. In doing so, we create a safe, open, and independent space where everyone can find and share insights.
**Priority content workstreams to deliver major update before summer 2026**
* **Agentic AI**: Extending the Exchange further with the emerging security challenges of autonomous multi-agent systems, led by Chris Cochran
* **Harmonization**: Solving gaps and mapping the Exchange to leading frameworks including NIST, MITRE ATLAS, and ETSI led by Rob van der Veer and Yuvaraj
* **Red Teaming** (Testing): Extending the testing section and evaluating open-source tools for Predictive and Generative AI to withstand adversarial attack led by Behnaz Karimi
* **EU AI Act Flow Back**: Integration of the extensive research the group did for the contributions to the EU AI Act security standard, led by Rob van der Veer
* **Step-by-Step Guide**: Providing organizations with a structured path to implement AI security processes, led by Aruneesh Salhotra.
**Specialized Project Groups**
* **Risk Analysis**: Designing formal processes for AI risk assessment and responsibility assignment.
* **Education Guidance**: Providing training guidance and security mindsets for data scientists and developers.
* **Legislation**: Tracking global laws and regulations.
* **Requirements**: The group working on the AI Act and ISO 27090 contributions
* **Mathematical**: Ensuring completeness of the mathematical data science topics for AI robustness and security.
**Strategic & Operational Workstreams**
* **Standards alignment**: Through engagements, partnerships, events, and mapping, drive alignment of standards when it comes to AI security. Goal: clarity for practitioners and supervisors. Led by Rob van der Veer and Aruneesh Salhotra
* **Promotion & Outreach**: Development of global and regional marketing plans to drive community engagement and project visibility, led by Aruneesh Salhotra.
* **Sponsorship & Fundraising**: Operational efforts to secure the necessary resources and funding to sustain project growth, led by Aruneesh Salhotra. Core Technical Workstreams
**Project Leadership Team**
* Rob van der Veer: Project Founder and Lead Editor.
* Aruneesh Salhotra: Leads Promotion, Collaboration, and Fundraising.
* Behnaz Karimi: Leads Red Teaming, Training, and People Matters.
### このドキュメントの使い方
> カテゴリ: ディスカッション\
> パーマリンク:
The AI Exchange is a single coherent resource on the security and privacy of AI systems, presented on this website, divided over several pages - containing threats, controls, guidelines, tests and references.
**Ways to start, depending on your need:**
* **Ask any question on AI Security** Ask an AI security/privacy question based on the content of the Exchange: [AI Exchange AGENT](https://notebooklm.google.com/notebook/75840a00-78f8-454d-ad4d-9ac27ae4cf48) (uses Google service so requires Google account).
* **Learn what the AI Exchange is**:\
See [About](https://owaspai.org/go/about/)
* **Start AI security as organization**:\
See [How to organize AI security](https://owaspai.org/go/organize/)..
* **Start AI security as individual**:\
See 'Learn AI security' below to familiarize yourself with the threats and controls or look in the [references section](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/references/README.md) for a large table with training material.
* **Secure a system**:\
If you want your **AI system to be secure**, start with [risk analysis](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/riskanalysis/README.md) to guide you through a number of questions, resulting in the threats that apply. And when you click on those threats you'll find the controls (countermeasures) to check for, or to implement. Alternatively, you can let our [AGENT](https://notebooklm.google.com/notebook/75840a00-78f8-454d-ad4d-9ac27ae4cf48) ask YOU questions about your system and threat model for you. Use this prompt: "Can you look at the risk analysis section and ask me in a few iterations the relevant questions from that section about my AI system, to determine what threats apply to my system, according to the AI Exchange, and give me the permalinks of those threats as hyperlinks to click on?"
* **Learn AI security**:
* Step 1: First study the brief [AI security essentials](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/essentials/README.md) for the **big picture**.
* Step 2: **Select** the threats that are relevant to your practice, by looking at [threat modeling](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/threatmodel/README.md) - or let AI interview you to find out (see above), or skip this step if you want to learn the complete threat picture.
* Step 3: If you're involved in **Agentic AI**, see the brief discussion of how [agentic threats](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/agenticaithreats/README.md) are covered.
* Step 4: If you run a **ready-made model**, have a look at the [threat model on ready-made models](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/readymademodel/README.md).
* Step 5: See your **threats** in their context \*\* in the [AI threat model](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/threatsoverview/README.md) and the [AI security matrix](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/aisecuritymatrix/README.md).
* Step 6: Click on your relevant threats in that overview to get more information and how to protect against it.
* Step 7: To find out what to do against a specific threat, check the **Controls** section of that threat, or the [periodic table](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/periodictable/README.md) which lists the controls for every threat.
* Step 8: To learn about the bigger picture how controls play a role, and interact: see the [controls overview](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/controlsoverview/README.md)
* Step 9: If **privacy** is in scope for you: see [the privacy section](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/aiprivacy/README.md).
* Step 10: If you're involved in **testing**: see [the testing section](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/testing/README.md).
* Step 11: A great way to better understand AI threats is to act as an attacker, for which we recommend [PwnzzAI!](https://github.com/OWASP/PwnzzAI): a hacking lab project with the Exchange as founding partner. A great exercise!
* To learn more about education programs, see [#SEC EDUCATE](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/seceducate/README.md)
* If you prefer one document: download a [snapshot of the Exchange in pdf](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/OWASP-AI-Exchange.pdf).
* **Lookup**:
* To look up a specific topic, use the search function or the [index](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/index/README.md).
* Looking for more information, or training material: see the [references](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/references/README.md).
The AI exchange covers both heuristic artificial intelligence (e.g., expert systems) and machine learning. This means that when we talk about an AI system, it can for example be a Large Language Model, a linear regression function, a rule-based system, or a lookup table based on statistics. Throughout this document, it is made clear which threats and controls play a role and when.
**The structure**\
You can see the high-level structure on the [main page](https://owaspai.org). On larger screens you can see the structure of pages on the left sidebar and the structure within the current page on the right. On smaller screens you can view these structures through the menu. There is also a section with the most important topics in a [Table of contents](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/toc/README.md).
The main structure is made of the following pages:\
(0) [AI security overview - this page](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/toc/README.md), contains an overview of AI security and discussions of various topics.\
(1) [General controls, such as AI governance](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/generalcontrols/README.md)\
(2) [Input threats, such as evasion attacks](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/inputthreats/README.md)\
(3) [Development-time threats, such as data poisoning](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/developmenttime/README.md)\
(4) [Runtime conventional security threats, such as leaking input](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/runtimeconventionalsec/README.md)\
(5) [AI security testing](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/testing/README.md)\
(6) [AI privacy](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/aiprivacy/README.md)\
(7) [References](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/references/README.md)
このページ (AI セキュリティ概要) では以下について取り上げます。
* 脅威の上位の概要
* 脅威とコントロールのさまざまな概要: マトリックス、周期表、ナビゲータ
* 関連する脅威とコントロールを選択するためのリスク分析
* さまざまな他のトピック: ヒューリスティックシステム、責任ある AI、生成 AI、NCSC/CISA ガイドライン、著作権
***
### High level view
This section discusses the main steps for adopting AI security in your organization, and for understanding the essentials of AI security.
#### AI セキュリティをどのように編成するか?
> カテゴリ: ディスカッション\
> パーマリンク:
Organizations: start here!\
人工知能 (AI) はとてつもない好機を与える一方で、セキュリティ脅威などの新たなリスクももたらします。そのため、潜在的な脅威とそれに対するコントロールを明確に理解した上で、AI アプリケーションに取り組むことが不可欠です。AI は信頼できる場合にのみ繁栄できます。
[](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/main/content/ai_exchange/static/images/guard.png)
The five steps - G.U.A.R.D - to organize AI security as an organization are:
1. **Govern**\
Start implementing general AI Governance so the organization can manage AI: know where it is applied, what people's responsibilities are, establish policies, do impact assessment, arrange [compliance](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/checkcompliance/README.md), organize [education](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/seceducate/README.md), et cetera. See [#AI Program](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/aiprogram/README.md) for guidance, including a quickstart. This is a general AI management process - not just security.
2. **Understand**
* Based on the inventory of your applications of AI and AI ideas, understand which threats apply, using the decision tree in the [risk analysis section](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/riskanalysis/README.md).
* Then make sure engineers and security professionals understand those relevant threats and their controls, using the guidance of the relevant [threat sections](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/threatsoverview/README.md) and the corresponding [process controls and technical controls](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/periodictable/README.md). Note that most of these controls are familiar conventional security countermeasures, unless you are training your own model.
* Use the courses and resources in the [references section](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/references/README.md) to support the understanding.
* Distinguish between controls that your organization has to implement, and those that are the responsibility of your supplier. Make the latter category part of your [supply chain management](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/supplychainmanage/README.md).
3. **Adapt**
* [セキュリティプラクティスを採用](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#secprogram) して、このドキュメントの AI セキュリティ資産、脅威、コントロールを含めます。
* Adapt your threat modelling to include the [AI security threat modeling](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/threatmodel/README.md) approach and do cross-team threat modelling, involving all engineers.
* Adapt your testing to include [AI-specific security testing](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/testing/README.md).
* Adapt your supply chain management to include [data, model, and hosting management](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/supplychainmanage/README.md) and to make sure that your suppliers are taking care of the identified threats.
* AI システムを開発する場合 (独自のモデルをトレーニングしない場合でも): Adapt your [software development practices](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devprogram/README.md) and [secure development program](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/secdevprogram/README.md) to involve AI engineering activities.
4. **Reduce**\
Reduce potential impact by [minimizing or obfuscating sensitive data](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/datalimit/README.md) and [limiting the impact of unwanted behaviour](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/limitunwanted/README.md) (e.g., managing privileges, guardrails, human oversight etc. Basically: apply Murphy's law.
5. **Demonstrate**\
Establish evidence of responsible AI security through transparency, [testing](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/testing/README.md), documentation, and communication. Prove to management, regulators, and clients that your AI systems are under control and that the applied safeguards work as intended.
And finally: think before you build an AI solution. AI can have fantastic benefits, but it always needs to be balanced with risks. Securing AI is typically harder than securing non-AI systems, first because it's relatively new, but also because there is a level of uncertainty in all data-driven technology. For example in the case of LLMs, we are dealing with the fluidity of natural language. LLMs essentially offer an unstable, undocumented interface with an unclear set of policies. That means that security measures applied to AI often cannot offer security properties to a standard you might be used to with other software. Consider whether AI is the appropriate technology choice for the problem you are trying to solve. Removing an unnecessary AI component eliminates all AI-related risks.
***
#### Essentials: how to understand the basics of AI security
> Category: discussion\
> Permalink:
This section serves as THE starting point to understand the foundations of AI security, and was established in close collaboration with industry and institutes, including complete alignment with the [SANS Critical AI security guidelines](https://assets.contentstack.io/v3/assets/bltabe50a4554f8e97f/blte964a6eef293d57e/whitepaper-critical-ai-security-guidelines).
**New threats** (overview [here](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/threatsoverview/README.md)):
1. [**Model input threats**](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/inputthreats/README.md):
* [Evasion](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/evasion/README.md): Misleading a model by crafting data to force wrong decisions
* [Prompt injection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/promptinjection/README.md): Misleading a model by crafting instructions to manipulate behaviour
* [Extracting data from the model](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/disclosureinoutput/README.md): training data, augmentation data (including system prompts), or input
* [Extracting of the model itself](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/modelexfiltration/README.md) by querying the model
* [Resource exhaustion](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/airesourceexhaustion/README.md) through use
2. **New suppliers** introduce threats of corrupted external [data](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/datapoison/README.md), [models](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/supplymodelpoison/README.md), and [model hosting](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/readymademodel/README.md)
3. **New AI assets** with conventional threats, notably:
* Training data / augmentation data (e.g. system prompts) - can leak and [poisoning](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/datapoison/README.md) this data manipulates model behaviour
* Model - can suffer from [leaking during development](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devmodelleak/README.md) or [leaking during runtime](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/runtimemodelleak/README.md) and when it comes to ingegrity: from [poisoning during development](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devmodelpoison/README.md) or [poisoning during runtime](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/runtimemodelpoison/README.md)
* Input - can [leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/inputdataleak/README.md)
* Output - can contain [injection attacks](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/outputcontainsconventionalinjection/README.md)
**New controls** (overview [here](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/controlsoverview/README.md)):
* Extend existing [Governance](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/aiprogram/README.md), [Risk](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/riskanalysis/README.md) and [Compliance](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/checkcompliance/README.md) - in order to secure AI, you need overview, analysis, policy, training, and responsibilities
* Extend existing **conventional security controls** to protect the AI-specific assets
* Extend [Supply chain management](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/supplychainmanage/README.md) to incorporate obtaining data, models, and hosting
* Specific **AI engineer controls**, to work against poisoning and model input attacks - next to conventional controls. This category is divided into **Data/model engineering** during development and **Model I/O handling** for runtime filtering, stopping or alerting to suspicious input or output. It is typically the territory of AI experts e.g. data scientists with elements from mathematics, statistics, linguistics and machine learning.
* [**Monitoring**](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/monitoruse/README.md) of model performance and inference - extending model I/O handing and overlooking general usage of the AI system
* **Impact limitation controls** (because of zero model trust: assume a model can be misled, make mistakes, or leak data):
* [Minimize or obfuscate sensitive data](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/datalimit/README.md)
* [Limit model behaviour](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/limitunwanted/README.md) (e.g., [oversight](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/oversight/README.md), [least model privilege](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/leastmodelprivilege/README.md), and [model alignment](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/modelalignment/README.md))
(\*) Note: Attackers that have a similar model (or a copy) can typically craft misleading input efficiently and without being noticed
[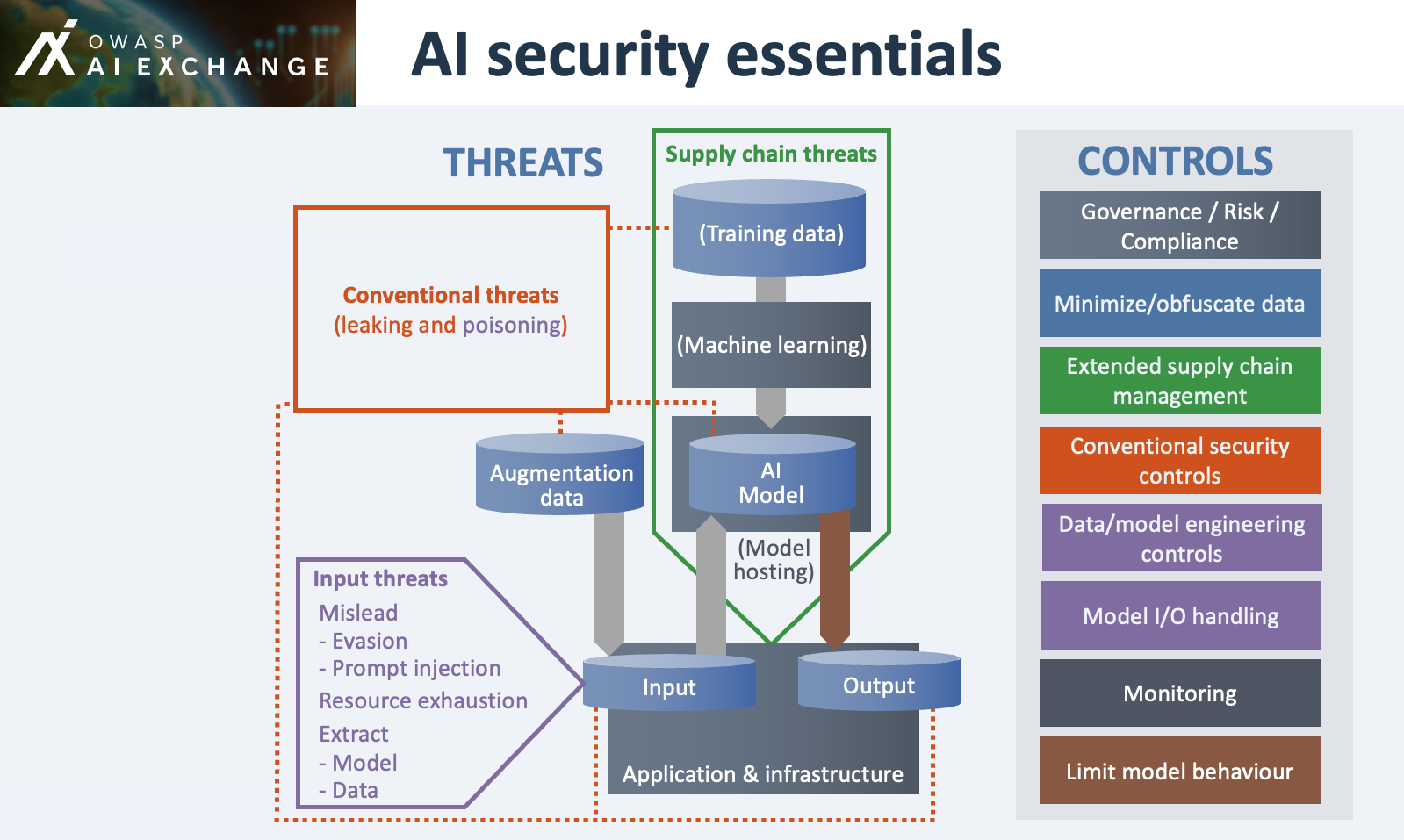](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/main/content/ai_exchange/static/images/essentials6.png)
Many experts and organizations contributed to this overview of essentials - including close collaboration with SANS Institute, ensuring alignment with SANS’ [Critical AI security guidelines](https://assets.contentstack.io/v3/assets/bltabe50a4554f8e97f/blte964a6eef293d57e/whitepaper-critical-ai-security-guidelines). SANS and the AI Exchange have a formal ongoing collaboration to share expertise and support broad education.
The upcoming sections provide overviews of AI security threats and controls.
***
### 脅威の概要
> カテゴリ: ディスカッション\
> パーマリンク:
#### Scope of Threats
In the AI Exchange we focus on AI-specific threats, meaning threats to AI assets (see [#SEC PROGRAM](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/secprogram/README.md)), such as training data. Threats to other assets are already covered in many other resources - for example the protection of a user database. AI systems are IT systems so they suffer from various security threats. Therefore, when securing AI systems, the AI Exchange needs to be seen as an extension of your existing security program: AI security = threats to AI-specific assets (AI Exchange) +threats to other assets (other resources)
#### 脅威ダイアグラム
私たちは三つのタイプの脅威を区別します:
1. 開発時 (データの取得および準備時、モデルの学習/取得時) の脅威 - 例: データポイズニング
2. 入力の脅威: 攻撃者によるモデル使用時 (推論時、入力の提供と出力の取得時) - 例: プロンプトインジェクションや回避
3. 実行時 (運用時、推論時ではない) のシステムへのその他の脅威 - 例: モデル入力の窃取
AI では、3 つのタイプの攻撃者の目的 (開示、欺瞞、妨害) に沿って、6 つのタイプの影響を概説します:
1. 開示: トレーニングデータやテストデータの機密性を損なう
2. 開示: モデル知的財産 (*モデルパラメータ* やそれにつながるプロセスとデータ) の機密性を損なう
3. 開示: 入力データや拡張データの機密性を損なう
4. 欺瞞: モデル動作の完全性を損なう (モデルが望ましくない動作をするように操作され、結果としてユーザーを欺く)
5. 妨害: モデルの可用性を損なう (モデルが機能しないか、望ましくない動作をする - ユーザーを欺くためではなく、通常の運用を妨害するため)
6. 開示/妨害: AI 固有ではない資産の機密性、完全性、可用性
このような影響をもたらす脅威はさまざまな攻撃対象領域を使用します。たとえば、トレーニングデータの機密性は開発中にデータベースにハッキングすることで侵害される可能性がありますが、特定の個人のデータを入力して、モデル出力の詳細を見るだけで、その個人がトレーニングデータにあるかどうかを知ることができる *メンバーシップ推論攻撃* によって漏洩する可能性もあります。
この図では脅威を矢印で示しています。各脅威には特定の影響があり、Impact legend を参照する文字で示されています。[コントロールの概要のセクション](#controls-overview) には、この図にコントロールのグループを追加したものがあります。この図の資産の一覧については、[セキュリティプログラムのサブセクション](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#sec-program) を参照してください。 [](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/main/content/ai_exchange/static/images/threats.png?v=2)
Note that some threats represent attacks consisting of several steps, and therefore present multiple threats in one, for example: — An adversary performs a data poisoning attack by hacking into the training database and placing poisoned samples, and then after the data has been used for training, presents specific inputs to make use of the corrupted behaviour. — An adversary breaks into a development environment to steal a model so it can be used to experiment on to craft manipulated inputs to achieve a certain goal, and then present that input to the deployed system.
#### Threats to agentic AI
> Category: discussion\
> Permalink:
In Agentic AI, AI systems can take action instead of just present output, and sometimes act autonomously or communicate with other agents. Important note: these are still software systems and AI systems, so everything in the AI Exchange applies, but there are a few attention points.
An example of Agentic AI is a set of voice assistants that can control your heating, send emails, and even invite more assistants into the conversation. That’s powerful—but you’d probably want it to check with you first before sending a thousand emails.
There are four typical properties of agentic AI:
1. Action: Agents don’t just chat — they invoke functions such as sending an email. That makes [LEAST MODEL PRIVILEGE](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/leastmodelprivilege/README.md) a key control.
2. Autonomous: Agents can trigger each other, enabling autonomous responses (e.g., a script receives an email, triggering a GenAI follow-up). That makes [OVERSIGHT](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/oversight/README.md) important, and it makes working memory an attack vector because that's where the state and the plan of an autonomous agent lives.
3. Complex: Agentic behaviour is emergent.
4. Multi-system: You often work with a mix of systems and interfaces. Because of that, developers tend to assign responsibilities regarding access control to the AI using instructions, opening up the door for manipulation through [prompt injection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/promptinjection/README.md).
What does this mean for security?
* Hallucinations and prompt injections can change commands — or even escalate privileges. Key controls are defense in depth and blast radius control ([impact limitation](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/limitunwanted/README.md)). Don’t assign the responsibility of access control to GenAI models/agents. Build that into your architecture.
* Existing assumptions about things like trust boundaries and other established security measures might need to be revisited because agentic AI changes interconnectivity and data flows between system components.
* Agents deployed with their own sets of permissions open up privilege escalation vectors because they are susceptible to becoming a confused deputy
* The attack surface is wide, and the potential impact should not be underestimated.
* Because of that, the [known controls](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/controlsoverview/README.md) become even more important, divided into:
* Prevention: for example: security of inter-model communication (e.g., MCP), [protecting of memory integrity](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/augmentationdataintegrity/README.md), and [prompt injection defenses](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/promptinjection/README.md)
* Blast radius control: [rule-based / human oversight](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/oversight/README.md) and [least model privilege](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/leastmodelprivilege/README.md)
* Observability: [monitoring](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/monitoruse/README.md)
For leaking sensitive data in agentic AI, you need three things, also called the *lethal trifecta*:
1. Data: Control of the attacker of data that find its way into an LLM at some point in the session of a user that has the desired access, to perform [indirect prompt injection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/indirectpromptinjection/README.md)
2. Access: Access of that LLM or connected agents to sensitive data
3. Send: The ability of that LLM or connected agents to initiate sending out data to the attacker
See [Simon Willison’s excellent work](https://simonwillison.net/2025/Jun/16/the-lethal-trifecta/) for more details, and for examples in agentic AI software development [here](https://www.darkreading.com/application-security/github-copilot-camoleak-ai-attack-exfils-data) and [here](https://ainativedev.io/news/malicious-github-issue-ai-agent-leak).
[Prompt injection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/promptinjection/README.md) and mostly the [indirect](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/indirectpromptinjection/README.md) form is the key threat in most agentic AI systems. See the [seven layers section](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/promptinjectionsevenlayers/README.md) on how these controls form layers of protection. After model alignment and filtering and detection, it should be assumed that prompt injection can still happen and therefore it is critical that *blast radius control* is performed.
Further links:
* For more details on the agentic AI threats, see the [Agentic AI threats and mitigations, from the GenAI security project](https://genai.owasp.org/resource/agentic-ai-threats-and-mitigations/).
* For a more general discussion of Agentic AI, see [this article from Chip Huyen](https://huyenchip.com/2025/01/07/agents.html).
* The [testing section](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/testing/README.md) discusses more about agentic AI red teaming and links to the collaboration between CSA and the Exchange: the Agentic AI red teaming guide.
* [OWASP Agentic AI security top 10](https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications-for-2026/) plus [Rock's blog on it](https://www.rockcybermusings.com/p/owasp-top-10-agentic-applications-security-guide)
* [Microsoft Pulse report on Agentic security](https://www.microsoft.com/en-us/security/security-insider/emerging-trends/cyber-pulse-ai-security-report)
#### AI セキュリティマトリクス
> カテゴリ: ディスカッション\
> パーマリンク:
以下の AI セキュリティマトリクス (クリックで拡大) は、主要な脅威とリスクを、タイプと影響の順に示しています。 [](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/main/assets/images/OwaspAIsecuritymatrix.png?v=3)
Clickable version, based on the [Periodic table](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/periodictable/README.md):
| Asset & Impact | Attack surface with lifecycle | Threat/Risk category |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Model behaviour Integrity | Runtime -Model use (provide input/ read output) | [Direct prompt injection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/directpromptinjection/README.md) |
| [Indirect prompt injection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/indirectpromptinjection/README.md) | | |
| [Evasion](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/evasion/README.md) (e.g., adversarial examples) | | |
| Runtime - Break into deployed model | [Model poisoning runtime](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/runtimemodelpoison/README.md) (reprogramming) | |
| Development -Engineering environment | [Direct development-environment model poisoning](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devmodelpoison/README.md) | |
| [Data poisoning of train/finetune data](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/datapoison/README.md) | | |
| Development - Supply chain | [Supply-chain model poisoning](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/supplymodelpoison/README.md) | |
| Training data Confidentiality | Runtime - Model use | [Disclosure in output](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/disclosureinoutput/README.md) |
| [Model inversion / Membership inference](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/modelinversionandmembership/README.md) | | |
| Development - Engineering environment | [Developmen-time data leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devdataleak/README.md) | |
| Model confidentiality | Runtime - Model use | [Model exfiltration](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/modelexfiltration/README.md) (input-output harvesting) |
| Runtime - Break into deployed model | [Direct runtime model leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/runtimemodelleak/README.md) | |
| Development - Engineering environment | [Direct development-time model-leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devmodelleak/README.md) | |
| Model behaviour Availability | Model use | [AI resource exhaustion](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/airesourceexhaustion/README.md) |
| Model input data Confidentiality | Runtime - All IT | [Input data leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/inputdataleak/README.md) |
| Any asset, CIA | Runtime-All IT | [Output contains conventional injection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/outputcontainsconventionalinjection/README.md) |
| Any asset, CIA | Runtime - All IT | Generic runtime security threats |
| Any asset, CIA | Runtime - All IT | Generic development-environment and supply-chain threats |
***
### コントロールの概要
> カテゴリ: ディスカッション\
> パーマリンク:
**Select and implement controls with care**\
The AI exchange lists a number of controls to mitigate risks of attack. Be aware that many of the controls are expensive to implement and are subject to trade-offs with other AI properties that can affect accuracy and normal operations of the model. Particularly, controls that involve changes to the learning process and data distributions can have un-intended downstream side effects, and must be considered and introduced with care.
**Scope of controls** In the AI Exchange we focus on AI-specific threats and their corresponding controls. Some of the controls are AI-specific (e.g., adding noise to the training set) and others are not (e.g., encrypting the training database). We refer to the latter as 'conventional controls'. The Exchange focuses on the details of the AI-specific controls because the details of conventional controls are specified elsewhere - see for example [OpenCRE](https://opencre.org). We do provide AI-specific aspects of those controls, for example that protection of model parameters can be implemented using a Trusted Execution Environment.
#### 脅威ダイアグラムとコントロール - 全般
下図は AI Exchange のコントロールをグループに分け、これらのグループを対応する脅威とともに適切なライフサイクルに配置したものです。 [](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/main/content/ai_exchange/static/images/threatscontrols.png?v=2) コントロールのグループは AI セキュリティをどのように対処するかをまとめたものです (コントロールは大文字です)。
* **AI ガバナンス**(1): AI リスクに対処するだけでなく、ライフサイクル全体に AI の考慮事項を組み込むことで、情報セキュリティとソフトウェアライフサイクルのプロセスに AI を包括的に統合します。
> ([AI PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#AIPROGRAM), [SEC PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECPROGRAM), [DEV PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#DEVPROGRAM), [SECDEV PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECDEVPROGRAM), [CHECK COMPLIANCE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#CHECKCOMPLIANCE), [SEC EDUCATE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECEDUCATE))
* データ、モデル、モデルホスティングのガバナンスにより **サプライチェーン管理を拡張します**(2):
> [SUPPLY CHAIN MANAGE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#SUPPLYCHAINMANAGE)
* AI システムは IT システムであるため、リスクに基づいて従来の **IT セキュリティコントロール**(2) を適用します。
* 標準的な **従来のセキュリティコントロール** (15408, ASVS, OpenCRE, ISO 27001 Annex A, NIST SP800-53 など) を完全な AI システムに適用し、新たな AI 固有の資産を忘れないようにします。
* 開発時: モデルとデータの保存、モデルとデータのサプライチェーン、データサイエンスの文書化
> [DEV SECURITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#DEVSECURITY), [SEGREGATE DATA](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#SEGREGATEDATA), [DISCRETE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#DISCRETE)
* 実行時: モデルの保存、モデルの使用、拡張データ (システムプロンプトを含む)、モデルの入出力
> [RUNTIME MODEL INTEGRITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#RUNTIMEMODELINTEGRITY), [RUNTIME MODEL IO INTEGRITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#RUNTIMEMODELIOINTEGRITY), [RUNTIME MODEL CONFIDENTIALITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#RUNTIMEMODELCONFIDENTIALITY), [MODEL INPUT CONFIDENTIALITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#MODELINPUTCONFIDENTIALITY), [ENCODE MODEL OUTPUT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#ENCODEMODELOUTPUT), [LIMIT RESOURCES](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#LIMIT-RESOURCES), [AUGMENTATION DATA CONFIDENTIALITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#AUGMENTATION-DATA-CONFIDENTIALITY), [AUGMENTATION DATA INTEGRITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#AUGMENTATION-DATA-INTEGRITY)
* 従来の IT セキュリティコントロールを **適応** して、AI により適したものにします (どの使用パターンを監視するかなど)。
> [MONITOR USE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#MONITOR-USE), [MODEL ACCESS CONTROL](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#MODEL-ACCESS-CONTROL), [RATE LIMIT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#RATE-LIMIT)
* **新規** の IT セキュリティコントロールを採用します。
> [CONF COMPUTE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#CONFCOMPUTE), [MODEL OBFUSCATION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#MODELOBFUSCATION), [INPUT SEGREGATION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#INPUT-SEGREGATION)
* 専門的な **AI エンジニアリングセキュリティコントロール**(3) を適用します。
* 開発の一環として振る舞いを制御するための生成 AI モデルエンジニアリングコントロール(3a):
> [MODEL ALIGNMENT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#MODEL-ALIGNMENT)
* モデル開発の一環としてのデータ/モデルエンジニアリングコントロール(3b)
> [FEDERATED LEARNING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#FEDERATEDLEARNING), [CONTINUOUS VALIDATION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#CONTINUOUSVALIDATION), [UNWANTED BIAS TESTING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#UNWANTEDBIASTESTING), [EVASION ROBUST MODEL](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#EVASION-ROBUST-MODEL), [POISON ROBUST MODEL](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#POISONROBUSTMODEL), [TRAIN ADVERSARIAL](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#TRAIN-ADVERSARIAL), [TRAIN DATA DISTORTION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#TRAINDATADISTORTION), [ADVERSARIAL ROBUST DISTILLATION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#ADVERSARIAL-ROBUST-DISTILLATION), [MODEL ENSEMBLE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#MODELENSEMBLE), [MORE TRAINDATA](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#MORETRAINDATA), [SMALL MODEL](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#SMALL-MODEL), [DATA QUALITY CONTROL](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#DATAQUALITYCONTROL))
* 攻撃をフィルタして検出するための実行時のモデル I/O 処理(3c)
> [ANOMALOUS INPUT HANDLING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#ANOMALOUS-INPUT-HANDLING), [EVASION INPUT HANDLING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#EVASION-INPUT-HANDLING), [UNWANTED INPUT SERIES HANDLING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#UNWANTED-INPUT-SERIES-HANDLING), [PROMPT INJECTION I/O HANDLING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#PROMPT-INJECTION-IO-HANDLING), [DOS INPUT VALIDATION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#DOS-INPUT-VALIDATION), [INPUT DISTORTION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#INPUT-DISTORTION), [ENSITIVE OUTPUT HANDLING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#SENSITIVEOUTPUTHANDLING), [OBSCURE CONFIDENCE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#OBSCURE-CONFIDENCE)
* **データを最小限に抑えます/難読化します**(4): 保存時および転送時の機密データ量を制限します。また、データの保存時間を開発時、実行時に制限します。
> ([DATA MINIMIZE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#DATAMINIMIZE), [ALLOWED DATA](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#ALLOWEDDATA), [SHORT RETAIN](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SHORTRETAIN), [OBFUSCATE TRAINING DATA](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#OBFUSCATETRAININGDATA))
* モデルが意図せず、または操作によって望ましくない方法で動作する可能性があるため、**モデルの動作を制限**(5) します。
> [OVERSIGHT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#OVERSIGHT), [LEAST MODEL PRIVILEGE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#LEASTMODELPRIVILEGE), [MODEL ALIGNMENT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#MODEL-ALIGNMENT), [AI TRANSPARENCY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#AITRANSPARENCY), [EXPLAINABILITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#EXPLAINABILITY), [CONTINUOUS VALIDATION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#CONTINUOUSVALIDATION), [UNWANTED BIAS TESTING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#UNWANTEDBIASTESTING)
すべての脅威とコントロールについては AI Exchange の対応する脅威セクションでより詳細に説明します。
#### Threat diagram with controls - ready-made model
> Category: discussion\
> Permalink:
If possible, and depending on price, organisations can prefer to use a ready-made model, instead of training or fine-tuning themselves. For example: an open source model to detect people in a camera image, or a general purpose LLM such as Google Gemini, OpenAI ChatGPT, Anthropic Claude, Alibaba QWen, Deepseek, Mistral, Grok or Falkon. Training such models yourself can cost millions of dollars, requires deep expertise and vast amounts of data.
The provider (e.g., OpenAI) has done the training/fine-tuning and therefore is responsible for part of security. Hence, proper supply chain management regarding the model provider is required.
The following deployment options apply for ready-made models:
* Closed source model, hosted by the provider - for the largest models typically the only available option
* Self-hosted: Open source model (open weights) deployed on-premise (most secure) or in the virtual private cloud (secure if the cloud provider is trusted) - these options provide more security and may be the best option cost-wise, but do not support the largest models
* Open source model (open weights) at a paid hosting service - convenient
**Self-hosted**
The diagram below shows threats and controls of a ready-made model in a self-hosting situation.
[](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/main/content/ai_exchange/static/images/threatscontrols-readymodel-selfhosted.png?v=2)
**External-hosted**
If the model is hosted externally, security largely depends on how the supplier handles data, including the security configuration. Some relevant questions to ask here include:
1. Where does the model run?\
Is the model running in the vendor's processes or in your own virtual private cloud? Some vendors say you get a 'private instance', but that may refer to the API, and not the model. If the model runs on the cluster operated by your vendor, your data leaves your environment in clear text. Vendors will minimize storage and transfer, but they may log and monitor.
2. What are the data retention rules?\
Has a court required the vendor to retain logs for litigation? This happened to OpenAI in the US for a period of time.
3. What is exactly logged and monitored?\
Read the small print. Is logging enabled, and if so, what is logged? And what is monitored - by operators or by algorithms? And in the case of monitoring algorithms: how is that infrastructure protected? Some vendors allow you to opt out of logging, but only with specific licenses.
4. Is your input used for training?\
This is a common fear, but in the vast majority of cases the input is not used. If vendors would do this secretly, it would get out because there are ways to tell.
If you can't accept the risk for certain data, then hosting your own (smaller) model is the safest option. Typically it won't be as good and there's the catch 22.
It is important to realise that a provider-hosted model needs your input data in clear text, because the model must read the data to process it. This means your sensitive data will exist unencrypted outside your infrastructure.\
This is not unique to LLM providers — it is the same for other multi-tenant SaaS services, such as commercial hosted Office suites. Even though providers usually minimise data storage, limit retention, and reduce data movement, the fact remains: your data leaves your environment in readable form.
When weighing this risk, compare it fairly: the vendor may still protect that environment better than you can protect your own.
The diagram below shows threats and controls of a ready-made model in an externally hosted situation.
[](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/main/content/ai_exchange/static/images/threatscontrols-readymodel-hosted.png?v=2)
A typical challenge for organizations is to control the use of ready-made-models for general purpose Generative AI (e.g., ChatGPT), since employees typically can access many of them, even for free. Some of these models may not satisfy the organization's requirements for security and privacy. Still, employees can be very tempted to use them with the lack of a better alterative, sometimes referred to as *shadow AI*. The best solution for this problem is to provide a good alternative in the form of an AI model that has been deployed and configured in a secure and privacy-preserving way, of sufficient quality, and complying with the organization's values and policies. In addition, the risks of shadow AI need to be made very clear to users.
#### AI セキュリティの周期表
> カテゴリ: ディスカッション\
> パーマリンク:
OWASP AI Exchange によって作成された以下の表は、AI に対するさまざまな脅威と、それに対して使用できるコントロールを示しています。すべての資産、影響、攻撃対象領域について整理しており、AI Exchange ウェブサイトの包括的なカバレッジへのディープリンクを付与しています。 [一般的なガバナンスコントロール](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#11-general-governance-controls) はすべての脅威に適用されることに注意してください。
| 資産と影響 | ライフサイクルと攻撃対象領域 | 脅威/リスクのカテゴリ | コントロール |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| モデル動作の完全性 | ランタイム - モデル使用 (入力の提供 / 出力の読み取り) | [直接的プロンプトインジェクション](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#221-direct-prompt-injection) | [望ましくない動作の制限](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#13-controls-to-limit-the-effects-of-unwanted-behaviour), [監視](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#MONITOR-USE), [レート制限](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#RATE-LIMIT), [モデルアクセス制御](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#MODEL-ACCESS-CONTROL) プラス:, [プロンプトインジェクション I/O 処理](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#PROMPT-INJECTION-IO-HANDLING), [モデルアラインメント](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#MODEL-ALIGNMENT) |
| [間接的プロンプトインジェクション](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#222-indirect-prompt-injection) | [望ましくない動作の制限](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#13-controls-to-limit-the-effects-of-unwanted-behaviour), [プロンプトインジェクション I/O 処理](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#PROMPT-INJECTION-IO-HANDLING), [入力セグリゲーション](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#INPUT-SEGREGATION) | | |
| [回避](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#21-evasion) (例: 敵対的事例) | 望ましくない動作の制限, 監視, レート制限, モデルアクセス制御 追補:
異常な入力処理, 回避入力処理, 望ましくない入力シリーズ処理, 回避ロバストモデル, 敵対的トレーニング, 入力の歪曲, 敵対的ロバスト蒸留
| | |
| ランタイム - デプロイされるモデルへの侵入 | [直接的な実行時モデルポイズニング](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#42-direct-runtime-model-poisoning) (リプログラミング) | [望ましくない動作の制限](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#13-controls-to-limit-the-effects-of-unwanted-behaviour), [実行時のモデルの完全性](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#RUNTIMEMODELINTEGRITY), [実行時のモデル入出力の完全性](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#RUNTIMEMODELIOINTEGRITY) | |
| 開発時 - エンジニアリング環境 | [直接的な開発時モデルポイズニング](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#312-development-time-model-poisoning) | 望ましくない動作の制限, 開発環境のセキュリティ, データセグリゲーション, 連合学習, サプライチェーンマネジメント 追補:
モデルアンサンブル
| |
| [トレーニングデータやファインチューニングデータのデータポイズニング](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#311-data-poisoning) | 望ましくない動作の制限, 開発環境のセキュリティ, データセグリゲーション, 連合学習, サプライチェーンマネジメント 追補:
モデルアンサンブル 追補:
トレーニングデータの増強, データ品質コントロール, トレーニングデータの歪曲, ポイズンロバストモデル, 敵対的トレーニング
| | |
| 開発時 - サプライチェーン | [サプライチェーンのモデルポイズニング](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#313-supply-chain-model-poisoning) | 望ましくない動作の制限,
サプライヤ: 開発環境のセキュリティ, データセグリゲーション, 連合学習
プロデューサー: サプライチェーンマネジメント 追補:
モデルアンサンブル
| |
| トレーニングデータの機密性 | ランタイム - モデル使用 | [出力での開示](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#231-disclosure-of-sensitive-data-in-model-output) | 機密データ制限 (データの最小化, 短期保持, トレーニングデータの難読化) 追補:
監視, レート制限, モデルアクセス制御 追補:
機密性の高い出力処理
|
| [モデル反転とメンバーシップ推論](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#232-model-inversion-and-membership-inference) | 機密データ制限 (データの最小化, 短期保持, トレーニングデータの難読化) 追補:
監視, レート制限, モデルアクセス制御 追加:
望ましくない入力シリーズ処理, 曖昧な信頼性, スモールモデル
| | |
| 開発時 - エンジニアリング環境 | [直接的なトレーニングデータ漏洩](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#321-development-time-data-leak) | 機密データ制限 (データの最小化, 短期保持, トレーニングデータの難読化) 追補:
開発環境のセキュリティ, データセグリゲーション, 連合学習
| |
| モデルの機密性 | ランタイム - モデル使用 | [モデル抽出](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#24-model-exfiltration) (入出力ハーベスティング) | 監視, レート制限, モデルアクセス制御 追加:
望ましくない入力シリーズ処理
|
| ランタイム - デプロイされるモデルへの侵入 | [直接的な実行時モデル漏洩](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#43-direct-runtime-model-leak) | [ランタイムモデルの機密性](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#RUNTIMEMODELCONFIDENTIALITY), [モデルの難読化](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#MODELOBFUSCATION) | |
| 開発時 - エンジニアリング環境 | [直接的な開発時モデル漏洩](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#322-direct-development-time-model-leak) | [開発環境のセキュリティ](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#DEVSECURITY), [データセグリゲーション](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#SEGREGATEDATA), [連合学習](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#FEDERATEDLEARNING) | |
| モデル動作の可用性 | モデル使用 | [AI リソース枯渇](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#25-ai-resource-exhaustion) (モデルリソースの枯渇) | 監視, レート制限, モデルアクセス制御 追補:
サービス拒否の入力バリデーション, リソースの制限
|
| モデル入力データの機密性 | ランタイム - すべての IT | [入力データ漏洩](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#45-input-data-leak) | [モデル入力の機密性](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#MODELINPUTCONFIDENTIALITY) |
| 任意の資産, CIA | ランタイム - すべての IT | [従来のインジェクションを含む出力](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#44-output-contains-conventional-injection) | [モデル出力のエンコード](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#ENCODEMODELOUTPUT) |
| 任意の資産, CIA | ランタイム - すべての IT | 一般的な実行時セキュリティ脅威 | 従来のランタイムセキュリティコントロール |
| 任意の資産, CIA | ランタイム - すべての IT | 一般的な開発環境とサプライチェーンの脅威 | 従来の開発セキュリティとサプライチェーンマネジメントコントロール |
#### 詳細セクションにおける脅威とコントロールの構造
> カテゴリ: ディスカッション\
> パーマリンク:
このリソースの次の大きなページは、すべての AI セキュリティ脅威とそのコントロールに関する広範な詳細です。 以下のナビゲータ図は詳細セクションの構造を示し、脅威、コントロール、関連するリスク、適用されるコントロールの種類の間の関係を示しています。
画像をクリックすると、クリック可能なリンクを含む PDF を取得できます。
[](https://github.com/OWASP/www-project-ai-security-and-privacy-guide/raw/main/assets/images/owaspainavigator.pdf)
***
### 関連する脅威とコントロールをどのように選択するか? リスク分析
> カテゴリ: ディスカッション\
> パーマリンク:
There are quite a number of threats and controls described in this document. The relevance and severity of each threat and the appropriate controls depend on your specific use case and how AI is deployed within your environment. Determining which threats apply, to what extent, and who is responsible for implementing controls should be guided by a risk assessment based on your architecture and intended use. Simply go to the 'Identifying risks' section below and follow the steps.
**リスクマネジメント入門**\
組織はリスクをいくつかの主要な領域に分類します。戦略、運用、財務、コンプライアンス、評判、テクノロジ、環境、社会、ガバナンス (ESG) です。脅威は一つ以上の脆弱性を悪用するとリスクになります。このリソースで説明しているように、AI の脅威は複数のリスク領域にわたって大きな影響を及ぼす可能性があります。たとえば、AI システムに対する敵対的攻撃は、運用の中断、財務モデルの歪曲、コンプライアンスの問題を引き起こす可能性があります。AI 関連の脅威、リスク、潜在的な影響の概要については [AI セキュリティマトリクス](#ai-security-matrix) を参照してください。
AI システムの一般的なリスクマネジメントは、通常、AI ガバナンス ([AIPROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#AIPROGRAM) を参照) によって推進され、関連する AI システムによるリスクとそれらのシステムに対するリスクの両方を含みます。セキュリティリスク評価は、通常、セキュリティマネジメントシステム ([SECPROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECPROGRAM) を参照) によって推進され、このシステムは、AI 資産、AI 脅威、AI システムを含めることが求められます (これらが対応するリポジトリに追加されている場合)。ISO/IEC 27005 はセキュリティリスク管理の国際標準です。
組織は一般的に ISO 31000 または ISO 23894 などの類似の規格に基づくリスクマネジメントフレームワークを採用することがよくあります。これらのフレームワークは下記の四つの主要なステップを通じてリスク管理のプロセスをガイドします。
1. **リスクの特定**:\
組織などに影響を及ぼす可能性のある潜在的なリスクを認識します。
2. **リスクの評価**:\
リスクが顕在化した場合の影響の発生可能性と深刻度を推定することにより、リスク発生の確立を評価し、リスクが顕在化した場合の潜在的な結果を評価する必要があります。発生可能性と深刻度の組み合わせがリスクのレベルを表します。これは一般的に発生可能性と深刻度を組み合わせたヒートマップの形で提示されます。
3. **リスク処置**:\
リスク処置はリスクに対処するための適切な戦略を選択することを意味します。これらの戦略には、リスクの軽減、移転、回避、受容があります。詳細については以下を参照してください。
4. **リスクコミュニケーションとモニタリング**:\
リスク情報を利害関係者と定期的に共有し、リスクマネジメント活動に対する意識と継続的な支援を確保します。効果的なリスク処置を確実に適用します。これには、リスクとその属性 (深刻度、処置計画、オーナーシップ、ステータスなど) の包括的なリストであるリスク登録簿が必要です。これについては以降のセクションでさらに詳しく説明します。
5. 上記のプロセスを定期的に、および変更が必要になったときに、繰り返します。
リスクマネジメントの手順を一つずつ見てきましょう。
#### 1. リスクの特定 - 脅威モデルの決定ツリー
> Category: discussion\
> Permalink:
The AI Exchange presents a foundational framework of threats and controls. This catalog of threats can be used to identify the risks that apply to a specific AI system, depending on architecture, context, domain and use case.\
NOTE: In this document, we focus on AI-specific risks only - meaning risks to the AI-specific assets.
This subsection takes you through each type of risk impact, and poses questions that will help to determine which threats apply. In addition, it provides guidance to translate that to risks.
In essence, this is a 'Threat modeling' process: the bridge between a list of threats and a set of concrete, prioritized risks.\
The threats represent a catalogue of “attacks that could happen” and threat modeling answers three key questions:
1. Which threats theoretically apply to this system?
2. How could they realistically happen?
3. What would the impact be?
The step after that is detailed in the following subsection 2: to look in more detail at likelihood and impact.
The image below represents the AI Exchange threat modelling one-pager. It summarizes the step-by-step decision tree approach from this section. How to use:
1. Walk by each threat
2. Base on the column ‘When’, determine when that threat applies in theory
3. If the threat applies in theory, use the column ‘Impact’ to help decide whether the risk needs to be treated or not, depending on the level of harm for the use case.
The result: you start big, but you end up with a relatively small list of risks to focus on.
For example: You don’t have to protect against model inversion attacks that try to steal your training data, if that data isn’t sensitive. It sounds obvious, but I’ve seen many cases of protections in place for threats that effectively don’t matter.
Another example: If your agentic system uses an LLM, then it is in theory susceptible to indirect prompt injection: malicious instructions in untrusted data that manipulate agent behaviour. But if your only concern is that sensitive company data leaks, and there is no way for the system to send data to an attacker (e.g., email), then this threat remains theoretical. The risk does not have to be treated.
[](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/main/content/ai_exchange/static/images/threatmodelonepager.png)
**望ましくないモデルの動作のリスクと影響を特定する**
モデルの動作に関しては、このドキュメントのスコープがセキュリティであるため、攻撃者による操作に焦点を当てています。その他の望ましくない動作の原因には一般的な不正確さ (ハルシネーションなど) や特定のグループに関する望ましくない偏見 (差別) があります。
> QUESTION: Is the model GenAI (e.g., a Large Language Model) and not classic machine learning or a heuristic model? If Yes:
* Consider the threat of [direct prompt injection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/directpromptinjection/README.md) in case a) an attacker can provide input to the model (e.g., a prompt), and b) the model could theoretically create output that results in harm - for example: offensive output, information leading to harm, or triggering harmful functions (Agentic AI).
* For risk assessment of direct prompt injection, the first question is: has the model supplier done enough according to your risk appetite. For this, you can check tests that the supplier or others have performed, and when not available: have these tests done based on what harm means in your use case. What you accept, in other words: what you find too much effort in combination with too harmful, depends on your context. If a user wants the AI to say something offensive: do you regard it as a problem if that user succeeds in getting offended? Do you regard it as a problem if users can get a recipe to make poison - given that they can get this from many other AI's out there. See the linked prompt injection section for more details.
* Consider the threat of [indirect prompt injection](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/indirectpromptinjection/README.md) when your system inserts untrusted data in a prompt e.g. you retrieve somebody's resume and include it in a prompt, or an agent retrieves data that is untrusted (i.e. may have been manipulated or placed by an attacker).
> QUESTION: Who trains/finetunes the model?
* The supplier: consider the threat of[Supply chain model poisoning](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/supplymodelpoison/README.md): obtaining or working with a model that has been manipulated to behave in unintended ways.
* Mitigation guidance: This is done through proper [supply chain management](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/supplychainmanage/README.md) (e.g., selecting a trustworthy supplier and verifying the authenticity of the model). This is to gain assurance on the security posture of the provider, meaning the provider prevents model poisoning during development, including data poisoning, and uses uncompromised data. If the risk of data poisoning remains unacceptable, implementing post-training countermeasures can be an option if you have the expertise and if you have access to the model parameters (e.g., open source weights). See [POISONROBUSTMODEL](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/poisonrobustmodel/README.md). Note that providers are typically not very open about their security countermeasures, which means that it can be challenging to gain sufficient assurance. Regulations will hopefully help achieve more provider transparency. For more details, see [ready-made models](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/readymademodel/README.md).
* You: consider the threat of [data poisoning](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/datapoison/README.md) in the development environment or by obtaining poisoned data from a third party, and consider the threat of attackers altering your model directly using [direct development-time model poisoning](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devmodelpoison/README.md).
Why not train/finetune a model yourself? There are many third party and open source models that may be able to perform the required task, perhaps after some fine-tuning. Organizations often choose external GenAI models because they are typically general purpose, and training is difficult and expensive (often millions of dollars). Fine-tuning of generative AI is also not often performed by organizations given the cost of compute and the complexity involved. Some GenAI models can be obtained and run on your own infrastructure. The reasons for this can be lower cost (if it is an open source model), and the fact that sensitive input information does not have to be sent externally. A reason to use an externally hosted GenAI model can be the quality of the model.
> QUESTION: Does your system insert (augment) data to the input of your model, like for example in RAG (Retrieval Augmented Generation), or by inserting data from memory (e.g., stored state for an agent), or by having *system prompts* (standard instructions to the model that are automatically added to the input) ? If yes:
* Consider the threat of [augmentation data manipulation](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/augmentationdatamanipulation/README.md) as this data plays a role in determining the model behaviour.
* Is this augmentation data stored in a database for the purpose of the AI system (e.g., a vector database)? If Yes: you need to protect against [direct augmentation data leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/augmentationdataleak/README.md). Note that this also counts for system prompts, if they are sensitive.
> QUESTION: Who runs the model?
* The supplier runs the model: select a trustworthy supplier through [supply chain management](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/supplychainmanage/README.md), to make sure the deployed model cannot be manipulated through ([runtime model poisoning](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/runtimemodelpoison/README.md)) - just the way you would expect any supplier to protect their running application from manipulation.
* You run the model: You need to consider the threat of [runtime model poisoning](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/runtimemodelpoison/README.md) where attackers change the model that you have deployed.
> QUESTION: Is the model (predictive AI or Generative AI) used in a classification task (e.g., spam or fraud detection)?
* Yes: Consider the threat of an [evasion attack](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/evasion/README.md) in which a user tries to fool the model into a wrong decision using data (not instructions). Here, the level of risk is an important aspect to evaluate - see below. The risk of an evasion attack may be acceptable.
**Analysing the risk of unwanted model behaviour**
> QUESTION: Can the model trigger actions (e.g., API calls depending on a model classification output, or an LLM agent that triggers actions or other agents? If Yes:
* This typically increases the impact of the risks mentioned above, depending on the action. The action can for example be adding an entry to a database, but also closing a watertight door in a ship. The threat is for example prompt injection or augmentation data manipulation, but the risk is that this leads to a specific impact (e.g., exfiltrating data, or un unsafe action in the physical world.)
> QUESTION: IF the model triggers actions, is there an action that is able to send data so it can be seen by an adversary, and is there sensitive data accessible in the system by one of the agents or actions that is reachable by the manipulated agent? If Yes:
* This combination of 1) manipulated model behaviour, 2) ability for the model to send data, and 3) ability for the model to access sensitive data is called the 'Lethal trifecta'. The impact is: data exfiltration. For more details, see [Agentic threats](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/agenticaithreats/README.md).
NOTE: a special form of exfiltrating and sending data to an adversary is through [injecting exfiltration in model output](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/outputcontainsconventionalinjection/README.md): a model is manipulated to output sensitive data in code which sends out sensitive data. This can be javascript executed in a browser (XSS), but more simple: a link to an image on the server of an adversary, where the URL contains the sensitive data. Or in a similar fashion: the output containing a link for the user to click on, to that same server.
In order to assess the level of risk for unwanted model behaviour through manipulation, consider what the motivation of an attacker could be. What could an attacker gain by misleading your model? Just a claim to fame? Could it be a disgruntled employee? Maybe a competitor? What could an attacker gain by a less conspicuous model behaviour attack, like an evasion attack or data poisoning with a trigger? Is there a scenario where an attacker benefits from fooling the model? An example where evasion IS interesting and possible: adding certain words in a spam email so that it is not recognized as such. An example where evasion is not interesting is when a patient gets a skin disease diagnosis based on a picture of the skin. The patient has no interest in a wrong decision, and also the patient typically has no control - well maybe by painting the skin. There are situations in which this CAN be of interest for the patient, for example to be eligible for compensation in case the (faked) skin disease was caused by certain restaurant food. This demonstrates that it all depends on the context whether a theoretical threat is a real threat or not. Depending on the probability and impact of the threats, and on the relevant policies, some threats may be accepted as risk. When not accepted, the level of risk is input to the strength of the controls. For example: if data poisoning can lead to substantial benefit for a group of attackers, then the training data needs to be given a high level of protection.
**Identify risks with the impace of leaking training data**
> QUESTION: Do you train/finetune the model yourself?
* If yes, is the training data sensitive? If so, you need to consider the threats of:
* [disclosure in model output](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/disclosureuse/README.md) in case the output can contain the sensitive data
* [model inversion](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/modelinversionandmembership/README.md)
* [direct training data leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devdataleak/README.md) from your engineering environment
* [membership inference](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/modelinversionandmembership/README.md) - but only when the fact that something or someone was part of the training data constitutes sensitive information. For example, when the training set consists of criminals and their history to predict criminal careers. Membership of that set gives away the person is a convicted or alleged criminal.
> QUESTION: do you use insert data into the input (e.g., by using RAG -retrieve data and insert it in the prompt)?
* Yes: apply the above to your augmentation data, as if it was part of the training set: as the repository data feeds into the model and can therefore be part of the output as well.
If you don't train/finetune the model, then the supplier of the model is responsible, but not accountable per se, for unwanted content in the training data. This can be poisoned data (see above), data that is confidential, or data that is copyrighted. It is important to check licenses, warranties and contracts for these matters, or accept the risk based on your circumstances.
**Identify risks with the impact of model theft**
> QUESTION: Do you train/finetune the model yourself and is it intellectual property or susceptible to an Evasion attack (see above)?
* If yes, then you need to consider the threats:
* [Model exfiltration](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/modelexfiltration/README.md)
* [Direct development-time model leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devmodelleak/README.md)
* [Source code/configuration leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/devcodeleak/README.md)
* [Direct runtime model leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/runtimemodelleak/README.md)
**Identify risks with the impact of leaking input data**
> QUESTION: Is your input data sensitive?
* Protect against [input data leak](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/inputdataleak/README.md). Especially if the model is run by a supplier, proper care needs to be taken to ensure that this data is minimized and transferred or stored securely. Review the security measures provided by the supplier, including any options to disable logging or monitoring on their end. Realise that most Cloud AI models have your input and output unencrypted in their infrastructure (just like documents in Google Suite and Microsoft 365). If you use the right license and configuration, you can prevent it from being stored or analysed. One risk that remains is that the government of the supplier may be forced to store and keep input and output to serve for subpoenas. If you're using a RAG system, remember that the data you retrieve and inject into the prompt also counts as input data. This often includes sensitive company information or personal data.
**Identify further risks**
> QUESTION: Does your model create text output?
* Protect against [insecure output handling](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/insecureoutput/README.md), for example, when you display the output of the model on a website and the output contains malicious Javascript.
> ALWAYS DO: Make sure to protect against [AI resource exhaustions](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/denialmodelservice/README.md) (actors overusing your AI causing availability problems and/or high cost)). If your model is run by a supplier, then certain countermeasures may already be in place to address this.
Since AI systems are software systems, they require appropriate conventional application security and operational security, apart from the AI-specific threats and controls mentioned in this section.
#### 2. 発生可能性と影響度の推定によるリスクの評価
To determine the severity of a risk, it is necessary to assess the likelihood of the risk occurring and evaluating the potential consequences should the risk materialize.
**Estimating the Likelihood:**\
Estimating the likelihood and impact of an AI risk requires a thorough understanding of both the technical and contextual aspects of the AI system in scope. The likelihood of a risk occurring in an AI system is influenced by several factors, including the complexity of the AI algorithms, the data quality and sources, the conventional security measures in place, and the potential for adversarial attacks. For instance, an AI system that processes public data is more susceptible to data poisoning and inference attacks, thereby increasing the likelihood of such risks. A financial institution's AI system, which assesses loan applications using public credit scores, is exposed to data poisoning attacks. These attacks could manipulate creditworthiness assessments, leading to incorrect loan decisions.
Examples of aspects involved in rating probability:
* Opportunity regarding attacker access (OWASP, FAIR - Factor Analysis for Information Risk)
* Risk of getting caught (FAIR)
* Capabilities/tools/budget (ISO/IEC 27005, OWASP, FAIR)
* Susceptibility of the system (ISO/IEC 27005, FAIR)
* Motive(OWASP, FAIR, ISO/IEC 27005)
* Number of potential attackers(OWASP)
* Data regarding incidents and attempts (ISO/IEC 27005)
**Evaluating the Impact:** Evaluating the impact of risks in AI systems involves understanding the potential consequences of threats materializing. This includes both the direct consequences, such as compromised data integrity or system downtime, and the indirect consequences, such as reputational damage or regulatory penalties. The impact is often magnified in AI systems due to their scale and the critical nature of the tasks they perform. For instance, a successful attack on an AI system used in healthcare diagnostics could lead to misdiagnosis, affecting patient health and leading to significant legal, trust, and reputational repercussions for the involved entities.
**Prioritizing risks** The combination of likelihood and impact assessments forms the basis for prioritizing risks and informs the development of Risk Treatment decisions. Commonly organizations use a risk heat map to visually categorize risks by impact and likelihood. This approach facilitates risk communication and decision-making. It allows the management to focus on risks with highest severity (high likelihood and high impact).
#### 3. リスク処置
Risk treatment is about deciding what to do with the risks: transfer, avoid, accept, or mitigate. Mitigation involves selecting and implementing controls. This process is critical due to the unique vulnerabilities and threats related to AI systems such as data poisoning, model theft, and adversarial attacks. Effective risk treatment is essential to robust, reliable, and trustworthy AI.
Risk Treatment options are:
1. **Mitigation**: Implementing controls to reduce the likelihood or impact of a risk. This is often the most common approach for managing AI cybersecurity risks. See the many controls in this resource and the 'Select controls' subsection below.\
\- Example: Enhancing data validation processes to prevent data poisoning attacks, where malicious data is fed into the Model to corrupt its learning process and negatively impact its performance.
2. **Transfer**: Shifting the risk to a third party, typically through transfer learning, federated learning, insurance or outsourcing certain functions. - Example: Using third-party cloud services with robust security measures for AI model training, hosting, and data storage, transferring the risk of data breaches and infrastructure attacks.
3. **Avoidance**: Changing plans or strategies to eliminate the risk altogether. This may involve not using AI in areas where the risk is deemed too high. - Example: Deciding against deploying an AI system for processing highly sensitive personal data where the risk of data breaches cannot be adequately mitigated.
4. **Acceptance**: Acknowledging the risk and deciding to bear the potential loss without taking specific actions to mitigate it. This option is chosen when the cost of treating the risk outweighs the potential impact. - Example: Accepting the minimal risk of model inversion attacks (where an attacker attempts to reconstruct publicly available input data from model outputs) in non-sensitive applications where the impact is considered low.
#### 4. リスクコミュニケーションとモニタリング
Regularly sharing risk information with stakeholders to ensure awareness and support for risk management activities.
A central tool in this process is the Risk Register, which serves as a comprehensive repository of all identified risks, their attributes (such as severity, treatment plan, ownership, and status), and the controls implemented to mitigate them. Most large organizations already have such a Risk Register. It is important to align AI risks and chosen vocabularies from Enterprise Risk Management to facilitate effective communication of risks throughout the organization.
#### 5. Arrange responsibility
For each selected threat, determine who is responsible for addressing it. By default, the organization that builds and deploys the AI system is responsible, but building and deploying may be done by different organizations, and some parts of the building and deployment may be deferred to other organizations, e.g. hosting the model, or providing a cloud environment for the application to run. Some aspects are shared responsibilities.
If some components of your AI system are hosted, then you share responsibility regarding all controls for the relevant threats with the hosting provider. This needs to be arranged with the provider by using a tool like the responsibility matrix. Components can be the model, model extensions, your application, or your infrastructure. See [Threat model of a ready-made model](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/readymademodel/README.md).
If an external party is not open about how certain risks are mitigated, consider requesting this information and when this remains unclear you are faced with either 1) accept the risk, 2) or provide your own mitigations, or 3) avoid the risk, by not engaging with the third party.
#### 6. Verify external responsibilities
For the threats that are the responsibility of other organisations: attain assurance whether these organisations take care of it. This would involve the controls that are linked to these threats.
Example: Regular audits and assessments of third-party security measures.
#### 7. Select controls
Next, for the threats that are relevant to your use-case and fall under your responsibility, review the associated controls, both those listed directly under the threat (or its parent category) and the general controls, which apply universally. See the [Periodic table](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/periodictable/README.md) for an overview of which controls mitigate the risks for each threat. For each control, consider its purpose and assess whether it's worth implementing, and to what extent. This decision should weigh the cost of implementation against how effectively the control addresses the threat, along with the level of the associated risk. These factors also influence the order in which you apply controls. Start with the highest-risk threats and prioritize low-cost, quick-win controls (the "low-hanging fruit").
Controls often have quality-related parameters that need to be adjusted to suit the specific situation and level of risk. For example, this could involve deciding how much noise to add to input data or setting appropriate thresholds for anomaly detection. Testing the effectiveness of these controls in a simulation environment helps you evaluate their performance and security impact to find the right balance. This tuning process should be continuous, using insights from both simulated tests and real-world production feedback.
When have you done enough? The AI system is sufficiently secure when all identified risks can be treated, meaning transferred, avoided or accepted, where acceptance in some cases can be done directly, without first taking action, and in other cases require you to implement controls to bring the risk to an acceptable level.
#### 8. Residual risk acceptance
In the end, you need to be able to accept the risks that remain regarding each threat, given the controls that you implemented.
#### 9. Further management of the selected controls
(see [SECPROGRAM](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/secprogram/README.md)), which includes continuous monitoring, documentation, reporting, and incident response.
#### 10. Continuous risk assessment
Implement continuous monitoring to detect and respond to new threats. Update the risk management strategies based on evolving threats and feedback from incident response activities.\
Example: Regularly reviewing and updating risk treatment plans to adapt to new vulnerabilities.
***
### ... についてはどうですか?
#### 機械学習以外の AI についてはどうですか?
AI を理解するのに役立つ方法は、AI が機械学習 (現在主流の AI タイプ) モデルと *ヒューリスティックモデル* から構成されていると考えることです。モデルはデータに基づいて計算方法を学習した機械学習モデルであることも、ルールベースのシステムなどの人間の知識に基づいて設計されたヒューリスティックモデルであることもあります。ヒューリスティックモデルは依然としてテストのためにデータを必要とし、場合によっては、人間が導出した知識のさらなる開発と検証をサポートする分析を実施するためにもデータが必要です。 このドキュメントは機械学習に焦点を当てています。とはいえ、ここではヒューリスティックシステムにも適用される、このドキュメントの機械学習の脅威を簡単に要約します。
* モデル回避はヒューリスティックモデルでも可能です。攻撃者は定義されたルールの抜け穴や弱点を見つけようとする可能性があります。
* モデル抽出 - ヒューリスティックモデルからの入出力の組み合わせに基づいて機械学習モデルを訓練できます。
* 使用による過度の依存 - ヒューリスティックシステムも過度に依存することがあります。適用された知識は誤りの可能性があります。
* データポイズニングとモデルポイズニングはどちらも、知識を強化するために使用されるデータの改竄や、開発時や実行時にルールを操作することによって発生する可能性があります。
* 分析やテストに使用されるデータの漏洩が依然として問題になる可能性があります。
* 知識、ソースコード、設定が知的財産である場合、機密データとみなされる可能性があり、保護が必要です。
* たとえばヒューリスティックシステムが患者を診断する必要がある場合、機密性の高い入力データが漏洩します。
#### 責任ある AI や信頼できる AI についてはどうですか?
> カテゴリ: ディスカッション\
> パーマリンク:
AI には、リスクを軽減しながら良い結果をもたらすという点で、さまざまな側面があります。これは、責任ある AI や信頼できる AI と呼ばれることが多く、前者は倫理、社会、ガバナンスを重視し、後者はより技術的、運用的側面を重視します。
主な責務がセキュリティであるなら、まず AI セキュリティに焦点を当てることが最善です。AI セキュリティをしっかりと理解したら、他の AI の側面にも知識を広げることです。たとえ、その領域に責任を負っている同僚をサポートし、警戒を怠らないようにするためであってもです。結局のところ、セキュリティ専門家は潜在的な障害点を見つけることが得意なことが多くあります。さらに、いくつかの側面は侵害された AI の結果である可能性があり、したがって *安全性 (safety)* などを理解しておくと役立ちます。
AI の原則を分析し、それぞれがセキュリティとどのように関連しているかを見てみましょう。
* **正確性 (Accuracy)** はその「ビジネス機能」を実行するのに十分に正しいかどうかを指します。不正確であると、(物理的な) 安全性の問題 (運転中に車のトランクが開いてしまうなど) やその他の有害な間違った判断 (ローンの不当な拒否など) などの危害につながる可能性があります。セキュリティとの関連は、ある種の攻撃が望ましくないモデル動作を引き起こすことであり、これは定義上、正確性の問題です。とはいえ、セキュリティの範囲ではそのような攻撃のリスクを軽減することに限定されており、正確なモデルの作成 (トレーニングセットの代表データの選択など) の問題全体を解決するものではありません。
* **安全性 (Safety)** は危害から保護されている、あるいは危害を引き起こす可能性が低い状態を指します。したがって、AI システムの安全性は危害 (一般的に物理的な危害を意味しますが、それに限定されません) のリスクがある場合の正確性のレベルのことであり、さらに (正確性とは別に) それらのリスクを軽減するために設けられたものです。これには正確性を保護するためのセキュリティに加えて、モデルのビジネス機能にとって重要な多くの安全性の対策を含みます。これらはセキュリティ上の理由だけでなく、他の理由 (不適切なトレーニングデータなど) でモデルが安全でない決定を下す可能性があるため、安全性とセキュリティの間で共通する懸念事項であることに注意する必要があります。
* 安全でない動作を制限するための [監視](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#OVERSIGHT)、およびそれに関連して、モデルへの最小権限の割り当て
* 正確性を保護するための [継続的バリデーション](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#CONTINUOUSVALIDATION)
* [透明性](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#AITRANSPARENCY): 下記参照
* [説明可能性](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#EXPLAINABILITY): 下記参照
* **透明性 (Transparency)**: アプローチに関する情報を共有すること、ユーザーおよび依存するシステムに正確性のリスクを警告すること、さらに、多くの場合、ユーザーは使用されているモデルについての詳細とそれがどのように作成されたかを知る権利を持っています。そのため、セキュリティ、プライバシー、安全性の間で共通する懸念事項になります。
* **説明可能性 (Explainability)**: 情報を共有すること、特定の結果がどのようにしてもたらされたかをより詳しく説明することで、ユーザーが正確性を検証するのに役立つこと。正確性を検証することとは別に、ユーザーが透明性を取得でき、異なる結果を得るには何を変更する必要があるかを理解することができます。そのため、セキュリティ、プライバシー、安全性、ビジネス機能の間で共通する懸念事項になります。特別なケースには、プライバシーとは別に説明可能性を法律で要求されている場合であり、この懸念を共有する側面のリストに「コンプライアンス」を追加します。
* **堅牢性 (Robustness)** は、入力に予期したバリエーションや予期しないバリエーションがあっても正確性を維持する能力です。セキュリティの範囲ではそのようなバリエーションが悪意のある場合 (*敵対的堅牢性*) に関するものであり、通常のバリエーション (*一般的堅牢性*) に対して必要な対策とは異なる対策が必要になることがよくあります。正確性の場合と同様に、セキュリティ自体は通常のバリエーションに対する堅牢なモデルの作成には関与しません。例外は一般的堅牢性、敵対的堅牢性が関連する場合であり、これは安全性とセキュリティの間で共通する懸念事項になります。どちらに当てはまるかは具体的なケースによって異なります。
* **差別からの自由 (Free of discrimination)** 保護された属性に望ましくないバイアスがない、つまり、モデルが特定のグループ (性別、民族など) を「不当に扱う」ような体系的な不正確さがないこと。差別は法的および倫理的な理由から望ましくありません。セキュリティとの関係は、望ましくないバイアスを検出することで、攻撃によって引き起こされる望ましくないモデル動作を特定するのに役立つことです。たとえば、データポイズニング攻撃はトレーニングセットに悪意のあるデータサンプルを挿入します。最初は気付かれませんが、モデル内の原因不明のバイアスが検出されることによって発見されます。「公平性 (fairness)」という用語は差別問題を指すために使用されることもありますが、プライバシーにおける公平性は、と名声、倫理的使用、プライバシー権など、個人に対する公平な扱いを指す幅広い用語であることがほとんどです。
* **共感性 (Empathy)**。AI アプリケーションを評価する際に、セキュリティが達成できる具体的な限界を認識することが、セキュリティとの関連性につながります。個人や組織が適切に保護できない場合、共感性とはアイデアを再考することを意味します。つまり、そのアイデアを完全に拒否するか、潜在的な危害を軽減するための追加の予防措置を講じることになります。
* **説明責任 (Accountability)**。説明責任とセキュリティの関係は、セキュリティ対策はその対策に至ったプロセスを含めて実証可能であるべきということです。さらに、セキュリティインシデントを検出し、再構築し、対応して、説明責任を果たすためには、他の IT システムと同様に、セキュリティ特性としてのトレーサビリティが重要です。
* **AI セキュリティ**。AI のセキュリティの側面は AI Exchange の中心的なトピックです。簡単に言うと、以下のように分けられます。
* [入力攻撃](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md)、モデルに入力を提供することで実行されます
* [モデルポイズニング](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#31-broad-model-poisoning-development-time)、モデルの動作を改変することを目的としています
* [開発時](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#32-sensitive-data-leak-development-time) または実行時 (下記参照) に、トレーニングデータ、モデル入力、出力、またはモデル自体などの AI 資産を盗みます
* さらに [実行時の従来のセキュリティ攻撃](https://coky-t.gitbook.io/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/pages/PLXJnwN7220KwrAswArc##41-non-ai-specific-application-security-threats)
[](https://raw.githubusercontent.com/OWASP/www-project-ai-security-and-privacy-guide/main/assets/images/aiwayfinder.png)
#### 生成 AI (LLM など) についてはどうですか?
> カテゴリ: ディスカッション\
> パーマリンク:
はい、生成 AI は現在の AI 変革をリードしており、AI セキュリティの中で最も急速に変化しているサブフィールドです。とはいえ、クレジットスコアリング、不正検出、医療診断、製品推奨、画像認識、予知保全、プロセス制御など、多くの重要なユースケースには他のタイプのアルゴリズム (*予測 AI* と呼びましょう) が引き続き適用されることを認識することが重要です。このドキュメントでは関連するコンテンツには「生成 AI」のマークを付けています。
重要な注意: セキュリティ脅威の観点からは、生成 AI は他の形式の AI (*予測 AI*) とそれほど違いはありません。生成 AI の脅威とコントロールは一般的な AI と大部分が重複しており、非常によく似ています。とはいえ、一部のリスクは (はるかに) 高くなります。低いものもあります。生成 AI 固有のリスクはごくわずかです。生成 AI と予測 AI ではコントロールカテゴリが大きく異なるものがあり、主にデータサイエンスコントロール (トレーニングセットへのノイズ追加など) です。多くの場合、生成 AI ソリューションはモデルをそのまま使用し、組織によるトレーニングを一切行わず、セキュリティ責任の一部を組織からサプライヤに移します。それでも、 [既製のモデル](#threat-model-with-controls---ready-made-model) を使用する場合は、依然としてそうした脅威に注意する必要があります。
LLM による主な新しい脅威は何ですか?
* まず第一に、LLM は脆弱性のあるコードを作成するために使用されたり、攻撃者がマルウェアを作成するために使用されたり、ハルシネーションによって害を及ぼす可能性があるため、セキュリティに新たな脅威をもたらします。しかし、これらの懸念事項は AI Exchange の範囲外であり、AI システム自体へのセキュリティ脅威に焦点を当てています。
* 入力について:
* プロンプトインジェクションは、攻撃者が細工した命令や、時には隠された命令で、モデルの動作を操作するものです。
* また、企業秘密や個人データを含む、大量のデータをプロンプトで送信する組織も新たにあります。
* 出力について: 出力にはインジェクション攻撃を含んだり、機密データや著作権で保護されたデータを含む可能性があるという事実が新たにあります ([著作権](#how-about-copyright) 参照)。
* 過度の依存は問題です。私たちは LLM に物事を制御および作成され、LLM がどれほど正しいかを過信し、また、LLM が操作されるリスクを過小評価していることがあります。その結果、攻撃は大きな影響を与えることになります。
* トレーニングについて: トレーニングセットは非常に大きく、公開データに基づいているため、データポイズニングを実行することは容易です。また、汚染された基礎モデルはサプライチェーンの大きな問題でもあります。
* 他の AI システムと同様に、生成 AI システムは出力に基づいてアクションをトリガーできますが、生成 AI の場合、モデル出力はアクションを実行 (メールの送信など) したり、他の AI システムをトリガーするための関数呼び出しを含むことがあります。詳細については [エージェント AI](#threats-to-agentic-ai) を参照してください。
生成 AI セキュリティの特徴は以下の通りです。
| No. | 生成 AI セキュリティの特徴 | OWASP for LLM TOP 10 |
| --- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| 1 | 生成 AI モデルはプロンプト内の自然言語によって制御されるため、[プロンプトインジェクション](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#22-prompt-injection) のリスクが生じます。直接プロンプトインジェクションはモデルを騙して望ましくない動作 (不快な言動など) をさせようとするもので、間接プロンプトインジェクションは第三者がこの目的 (決定を操作するなど) のためにプロンプトにコンテンツを注入するものです。 | ([OWASP for LLM 01:Prompt injection](https://genai.owasp.org/llmrisk/llm01/)) |
| 2 | 生成 AI モデルは一般的に非常に大規模なデータセットでトレーニングされているため、[機密データ](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#231-disclosure-of-sensitive-data-in-model-output) や [ライセンスされているデータ](#how-about-copyright) を出力する可能性が高くなりますが、モデルにはアクセス権限の制御が組み込まれていません。すべてのデータはモデルユーザーがアクセスできるでしょう。システムプロンプト、モデルアラインメント、出力フィルタリングに関していくつかのメカニズムが実装されているかもしれませんが、それらは一般的に完全ではありません。 | ([OWASP for LLM 02: Sensitive Information Disclosure](https://genai.owasp.org/llmrisk/llm02/)) |
| 3 | [データとモデルのポイズニング](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#31-broad-model-poisoning-development-time) は AI 全般の問題ですが、生成 AI ではトレーニングデータがインターネットなどの制御が困難なさまざまな情報源から供給される可能性があるため、リスクは一般的に高くなります。たとえば、攻撃者はドメインを乗っ取り、操作された情報を配置する可能性があります。 | ([OWASP for LLM 04: Data and Model Poisoning](https://genai.owasp.org/llmrisk/llm04/)) |
| 4 | 生成 AI モデルは不正確で幻覚を起こす可能性があります。これは AI 全般のリスク要因であり、さらに大規模言語モデル (生成 AI) は非常に機密性が高く知識を持っているという印象を与えることで事態を悪化させる可能性があります。要するに、これはモデルが間違っていたり、モデルが操作されていたりするという可能性を過小評価するリスクに関するものです。つまり、それぞれすべてのセキュリティコントロールに関連しています。最も強く結びつくのは [望ましくないモデル動作の影響を制限するためのコントロール](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#13-controls-to-limit-the-effects-of-unwanted-behaviour)、特に [最小モデル権限](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/1_general_controls.md#LEASTMODELPRIVILEGE) です。 | ([OWASP for LLM 06: Excessive agency](https://genai.owasp.org/llmrisk/llm06/)) および ([OWASP for LLM 09: Misinformation](https://genai.owasp.org/llmrisk/llm09/)) |
| 5 | [入力データ漏洩](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#45-input-data-leak): 生成 AI モデルはほとんどがクラウドに存在し、多くの場合は外部パーティによって管理されているため、プロンプトの漏洩のリスクが高まります。この問題は生成 AI に限定されるものではありませんが、生成 AI には特に 2 つのリスクがあります。1) モデルの使用にはプロンプトを介したユーザーとのやり取り、ユーザーデータの追加、対応するプライバシーやセンシティビティの問題が含まれます。2) 生成 AI モデルの入力 (プロンプト) には機密データ (企業秘密など) を持つ豊富なコンテキスト情報を含む可能性があります。後者の問題はたとえば、コンサルタント会社でこれまでに書かれたすべてのレポートのデータなど、*コンテキスト内学習 (In-Context Learning)* や *検索拡張生成 (Retrieval Augmented Generation, RAG)* で発生します。まず第一に、この情報はプロンプトとともにクラウドに移動し、第二に、システムは情報に対する本来のアクセス権を考慮しない可能性があります。 | LLM Top 10 でのカバーなし |
| 6 | 事前トレーニング済みモデルは操作されている可能性があります。事前トレーニングの概念は生成 AI に限ったことではありませんが、このアプローチは生成 AI ではごく一般的であり、 [サプライチェーンのモデルポイズニング](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#313-supply-chain-model-poisoning) のリスクを高めます。 | ([OWASP for LLM 03 - Supply chain vulnerabilities](https://genai.owasp.org/llmrisk/llm03/)) |
| 7 | [モデル反転とメンバーシップ推論](https://coky-t.gitbook.io/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/pages/pkmnjBAaKM6c2x3sOoyL##222-model-inversion-and-membership-inference) は生成 AI にとって低リスクまたはゼロリスクです。 | LLM Top 10 でのカバーなし、異なるアプローチを使用する LLM06 を除く、上記を参照 |
| 8 | 生成 AI の出力にはクロスサイトスクリプティングなどの [インジェクション攻撃](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#44-insecure-output-handling) を実行する要素を含むかもしれません。 | ([OWASP for LLM 05: Improper Output Handling](https://genai.owasp.org/llmrisk/llm05/)) |
| 9 | [リソース枯渇](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#24-failure-or-malfunction-of-ai-specific-elements-through-use) はどの IT システムでも問題になる可能性がありますが、生成 AI モデルは一般的に実行コストが高いため、過負荷になると不要なコストが発生する可能性があります。 | ([OWASP for LLM 10: Unbounded consumption](https://genai.owasp.org/llmrisk/llm10/)) |
生成 AI 参考情報:
* [OWASP LLM top 10](https://llmtop10.com/)
* [Demystifying the LLM top 10](https://blog.kloudzone.co.in/demystifying-the-owasp-top-10-for-large-language-model-applications/)
* [Impacts and risks of GenAI](https://arxiv.org/pdf/2306.13033.pdf)
* [LLMsecurity.net](https://llmsecurity.net/)
#### NCSC/CISA ガイドラインについてはどうですか?
> カテゴリ: ディスカッション\
> パーマリンク:
英国 NCSC / CISA の [安全な AI システム開発のガイドライン](https://www.ncsc.gov.uk/collection/guidelines-secure-ai-system-development) を AI Exchange のコントロールにマッピングします。 脅威とリンクしているコントロールを確認するには、[AI セキュリティの周期表](#periodic-table-of-ai-security) を参照してください。
Note that the UK Government drove an initiative through their DSIT department to build on these joint guidelines and produce the [DSIT Code of Practice for the Cyber Security of AI](https://www.gov.uk/government/publications/ai-cyber-security-code-of-practice/code-of-practice-for-the-cyber-security-of-ai#code-of-practice-principles), which reorganizes things according to 13 principles, does a few tweaks, and adds a bit more of governance. The principle mapping is added below, and adds mostly post-market aspects:
* Principle 10: Communication and processes associated with end-users and affected entities
* Principle 13: Ensure proper data and model disposal
1. 安全な設計
* 脅威とリスクに対するスタッフの意識を高めます (DSIT principle 1): #[SECURITY EDUCATE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECEDUCATE)
* システムに対する脅威をモデル化します (DSIT principle 3): #[SECURITY PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECPROGRAM) のリスク分析を参照してください
* 機能性とパフォーマンスだけでなくセキュリティも考慮してシステムを設計します (DSIT principle 2): #[AI PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#AIPROGRAM), #[SECURITY PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECPROGRAM), #[DEVELOPMENT PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#DEVPROGRAM), #[SECURE DEVELOPMENT PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECDEVPROGRAM), #[CHECK COMPLIANCE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#CHECKCOMPLIANCE), #[LEAST MODEL PRIVILEGE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#LEASTMODELPRIVILEGE), #[DISCRETE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#DISCRETE), #[OBSCURE CONFIDENCE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#OBSCURE-CONFIDENCE), #[OVERSIGHT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#OVERSIGHT), #[RATE LIMIT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#RATE-LIMIT), #[DOS INPUT VALIDATION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#DOS-INPUT-VALIDATION), #[LIMIT RESOURCES](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#LIMIT-RESOURCES), #[MODEL ACCESS CONTROL](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#MODEL-ACCESS-CONTROL), #[AI TRANSPARENCY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#AITRANSPARENCY)
* AI モデルを選択する際に、セキュリティの利点とトレードオフを考慮します すべての開発時のデータサイエンスコントロール (現在 13), #[EXPLAINABILITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#EXPLAINABILITY)
2. 安全な開発
* サプライチェーンを保護します (DSIT principle 7): #[SUPPLY CHAIN MANAGE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#SUPPLYCHAINMANAGE)
* 資産を特定、追跡、保護します (DSIT principle 5): #[DEVELOPMENT SECURITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#DEVSECURITY), #[SEGREGATE DATA](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#SEGREGATEDATA), #[CONFIDENTIAL COMPUTE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/3_development_time_threats.md#CONFCOMPUTE), #[MODEL INPUT CONFIDENTIALITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#MODELINPUTCONFIDENTIALITY), #[RUNTIME MODEL CONFIDENTIALITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#RUNTIMEMODELCONFIDENTIALITY), #[DATA MINIMIZE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#DATAMINIMIZE), #[ALLOWED DATA](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#ALLOWEDDATA), #[SHORT RETAIN](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SHORTRETAIN), #[OBFUSCATE TRAINING DATA](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#OBFUSCATETRAININGDATA) および #[SECURITY PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECPROGRAM) の一部
* データ、モデル、プロンプトを文書化します (DSIT principle 8): #[DEVELOPMENT PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#DEVPROGRAM) の一部
* 技術的負債を管理します: #[DEVELOPMENT PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#DEVPROGRAM) の一部
3. 安全な展開
* インフラストラクチャを保護します (DSIT principle 6): #[SECURITY PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECPROGRAM) の一部と「資産を特定、追跡、保護します」を参照してください
* モデルを継続的に保護します: #[INPUT DISTORTION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#INPUT-DISTORTION), #[FILTER SENSITIVE MODEL OUTPUT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#FILTER-SENSITIVE-MODEL-OUTPUT), #[RUNTIME MODEL IO INTEGRITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#RUNTIMEMODELIOINTEGRITY), #[MODEL INPUT CONFIDENTIALITY](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/4_runtime_application_security_threats.md#MODELINPUTCONFIDENTIALITY), #[PROMPT INJECTION I/O HANDLING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#PROMPT-INJECTION-IO-HANDLING), #[INPUT SEGREGATION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#INPUT-SEGREGATION)
* インシデント管理手順を策定します: #[SECURITY PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECPROGRAM) の一部
* 責任をもって AI をリリースします: #[DEVELOPMENT PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#DEVPROGRAM) の一部
* ユーザーが正しいことを簡単にできるようにします (DSIT principle 4, called Enable human responsibility for AI systems): #[SECURITY PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECPROGRAM) の一部, and also involving #[EXPLAINABILITY](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/explainability/README.md), documenting prohibited use cases, and #[HUMAN OVERSIGHT](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/oversight/README.md))
4. 安全な運用と保守
* システムの動作を監視します (DSIT principle 12 and similar to DSIT principle 9 - appropriate testing and validation): #[CONTINUOUS VALIDATION](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#CONTINUOUSVALIDATION), #[UNWANTED BIAS TESTING](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#UNWANTEDBIASTESTING)
* システムの入力を監視します: #[MONITOR USE](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#MONITOR-USE), #[DETECT ODD INPUT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#DETECT-ODD-INPUT), #[DETECT ADVERSARIAL INPUT](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/2_threats_through_use.md#DETECT-ADVERSARIAL-INPUT)
* セキュアバイデザインのアプローチに従ってアップデートを行います (DSIT principle 11: Maintain regular security updates, patches and mitigations): #[SECURE DEVELOPMENT PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECDEVPROGRAM) の一部
* 教訓を収集して共有します: #[SECURITY PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECPROGRAM) および #[SECURE DEVELOPMENT PROGRAM](/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/1_general_controls.md#SECDEVPROGRAM) の一部
#### How about copyright?
> Category: discussion\
> パーマリンク:
**Introduction**
AI and copyright are two (of many) areas of law and policy, (both public and private), that raise complex and often unresolved questions. AI output or generated content is not yet protected by US copyright laws. Many other jurisdictions have yet to announce any formal status as to intellectual property protections for such materials. On the other hand, the human contributor who provides the input content, text, training data, etc. may own a copyright for such materials. Finally, the usage of certain copyrighted materials in AI training may be considered [fair use](https://en.wikipedia.org/wiki/Fair_use).
**AI & Copyright Security**
In AI, companies face a myriad of security threats that could have far-reaching implications for intellectual property rights, particularly copyrights. As AI systems, including large data training models, become more sophisticated, they inadvertently raise the specter of copyright infringement. This is due in part to the need for development and training of AI models that process vast amounts of data, which may contain copyright works. In these instances, if copyright works were inserted into the training data without the permission of the owner, and without consent of the AI model operator or provider, such a breach could pose significant financial and reputational risk of infringement of such copyright and corrupt the entire data set itself.
The legal challenges surrounding AI are multifaceted. On one hand, there is the question of whether the use of copyrighted works to train AI models constitutes infringement, potentially exposing developers to legal claims. On the other hand, the majority of the industry grapples with the ownership of AI-generated works and the use of unlicensed content in training data. This legal ambiguity affects all stakeholders including developers, content creators, and copyright owners alike.
**Lawsuits Related to AI & Copyright**
Recent lawsuits (writing is April 2024) highlight the urgency of these issues. For instance, a class action suit filed against Stability AI, Midjourney, and DeviantArt alleges infringement on the rights of millions of artists by training their tools on web-scraped images.\
Similarly, Getty Images’ lawsuit against Stability AI for using images from its catalog without permission to train an art-generating AI underscores the potential for copyright disputes to escalate. Imagine the same scenario where a supplier provides vast quantities of training data for your systems, that has been compromised by protected work, data sets, or blocks of materials not licensed or authorized for such use.
**Copyright of AI-generated source code**
Source code constitutes a significant intellectual property (IP) asset of a software development company, as it embodies the innovation and creativity of its developers. Therefore, source code is subject to IP protection, through copyrights, patents, and trade secrets. In most cases, human generated source code carries copyright status as soon as it is produced.
However, the emergence of AI systems capable of generating source code without human input poses new challenges for the IP regime. For instance, who is the author of the AI-generated source code? Who can claim the IP rights over it? How can AI-generated source code be licensed and exploited by third parties?
These questions are not easily resolved, as the current IP legal and regulatory framework does not adequately address the IP status of AI- generated works. Furthermore, the AI-generated source code may not be entirely novel, as it may be derived from existing code or data sources. Therefore, it is essential to conduct a thorough analysis of the origin and the process of the AI-generated source code, to determine its IP implications and ensure the safeguarding of the company's IP assets. Legal professionals specializing in the field of IP and technology should be consulted during the process.
As an example, a recent case still in adjudication shows the complexities of source code copyrights and licensing filed against GitHub, OpenAI, and Microsoft by creators of certain code they claim the three entities violated. More information is available here: [: GitHub Copilot copyright case narrowed but not neutered • The Register](https://www.theregister.com/2024/01/12/github_copilot_copyright_case_narrowed/)
**Copyright damages indemnification**
Note that AI vendors have started to take responsibility for copyright issues of their models, under certain circumstances. Microsoft offers users the so-called [Copilot Copyright Commitment](https://www.microsoft.com/en-us/licensing/news/microsoft-copilot-copyright-commitment), which indemnifies users from legal damages regarding copyright of code that Copilot has produced - provided [a number of things](https://learn.microsoft.com/en-us/legal/cognitive-services/openai/customer-copyright-commitment) including that the client has used content filters and other safety systems in Copilot and uses specific services. Google Cloud offers its [Generative AI indemnification](https://cloud.google.com/blog/products/ai-machine-learning/protecting-customers-with-generative-ai-indemnification).\
Read more at [The Verge on Microsoft indemnification](https://www.theverge.com/2023/9/7/23863349/microsoft-ai-assume-responsibility-copyright-lawsuit) and [Direction Microsoft on the requirements of the indemnification](https://www.directionsonmicrosoft.com/blog/why-microsofts-copilot-copyright-commitment-may-not-mean-much-for-customers-yet/).
**Do generative AI models really copy existing work?**
Do generative AI models really look up existing work that may be copyrighted? In essence: no. A Generative AI model does not have sufficient capacity to store all the examples of code or pictures that were in its training set. Instead, during training, it extracts patterns about how things work in the data that it sees, and then later, based on those patterns, it generates new content. Parts of this content may show remnants of existing work, but that is more of a coincidence. In essence, a model doesn't recall exact blocks of code, but uses its 'understanding' of coding to create new code. Just like with human beings, this understanding may result in reproducing parts of something you have seen before, but not per se because this was from exact memory. Having said that, this remains a difficult discussion that we also see in the music industry: did a musician come up with a chord sequence because she learned from many songs that this type of sequence works and then coincidentally created something that already existed, or did she copy it exactly from that existing song?
**Mitigating Risk**
Organizations have several key strategies to mitigate the risk of copyright infringement in their AI systems. Implementing them early can be much more cost-effective than fixing at later stages of AI system operations. While each comes with certain financial and operating costs, the “hard savings” may result in a positive outcome. These may include:
1. Taking measures to mitigate the output of certain training data. The OWASP AI Exchange covers this through the corresponding threat: [sensitive data disclosure in model output](https://github.com/coky-t/owasp-ai-security-and-privacy-guide-ja/blob/main/go/disclosureinoutput/README.md).
2. Comprehensive IP Audits: a thorough audit may be used to identify all intellectual property related to the AI system as a whole. This does not necessarily apply only to data sets but overall source code, systems, applications, interfaces and other tech stacks.
3. Clear Legal Framework and Policy: development and enforcement of legal policies and procedures for AI use, which ensure they align with current IP laws including copyright.
4. Ethics in Data Sourcing: source data ethically, ensuring all data used for training the AI models is either created in-house, or obtained with all necessary permissions, or is sourced from public domains which provide sufficient license for the organization’s intended use.
5. Define AI-Generated Content Ownership: clearly defined ownership of the content generated by AI systems, which should include under what conditions it can be used, shared, disseminated.
6. Confidentiality and Trade Secret Protocols: strict protocols will help protect confidentiality of the materials while preserving and maintaining trade secret status.
7. Training for Employees: training employees on the significance and importance of the organization’s AI IP policies along with implications on what IP infringement may be will help be more risk-averse.
8. Compliance Monitoring Systems: an updated and properly utilized monitoring system will help check against potential infringements by the AI system.
9. Response Planning for IP Infringement: an active plan will help respond quickly and effectively to any potential infringement claims.
10. Additional mitigating factors to consider include seeking licenses and/or warranties from AI suppliers regarding the organization’s intended use, as well as all future uses by the AI system. With the help of a legal counsel, the organization should also consider other contractually binding obligations on suppliers to cover any potential claims of infringement.
**Helpful resources regarding AI and copyright:**
* [Artificial Intelligence (AI) and Copyright | Copyright Alliance](https://copyrightalliance.org/education/artificial-intelligence-copyright/)
* [AI industry faces threat of copyright law in 2024 | Digital Watch Observatory](https://dig.watch/updates/ai-industry-faces-threat-of-copyright-law-in-2024)
* [Using generative AI and protecting against copyright issues | World\
Economic Forum -weforum.org](https://www.weforum.org/agenda/2024/01/cracking-the-code-generative-ai-and-intellectual-property/)
* [Legal Challenges Against Generative AI: Key Takeaways | Bipartisan\
Policy Center](https://bipartisanpolicy.org/blog/legal-challenges-against-generative-ai-key-takeaways/)
* [Generative AI Has an Intellectual Property Problem - hbr.org](https://hbr.org/2023/04/generative-ai-has-an-intellectual-property-problem)
* [Recent Trends in Generative Artificial Intelligence Litigation in the\
United States | HUB | K\&L Gates - klgates.com](https://www.klgates.com/Recent-Trends-in-Generative-Artificial-Intelligence-Litigation-in-the-United-States-9-5-2023)
* [Generative AI could face its biggest legal tests in 2024 | Popular\
Science - popsci.com](https://www.popsci.com/technology/generative-ai-lawsuits/)
* [Is AI Model Training Compliant With Data Privacy Laws? - termly.io](https://termly.io/resources/articles/is-ai-model-training-compliant-with-data-privacy-laws/)
* [The current legal cases against generative AI are just the beginning |\
TechCrunch](https://techcrunch.com/2023/01/27/the-current-legal-cases-against-generative-ai-are-just-the-beginning/?guccounter=1)
* [(Un)fair Use? Copyrighted Works as AI Training Data — AI: The\
Washington Report | Mintz](https://www.mintz.com/insights-center/viewpoints/54731/2024-01-10-unfair-use-copyrighted-works-ai-training-data-ai)
* [Potential Supreme Court clash looms over copyright issues in\
generative AI training data | VentureBeat](https://venturebeat.com/ai/potential-supreme-court-clash-looms-over-copyright-issues-in-generative-ai-training-data/)
* [AI-Related Lawsuits: How The Stable Diffusion Case Could Set a Legal\
Precedent | Fieldfisher](https://www.fieldfisher.com/en/insights/ai-related-lawsuits-how-the-stable-diffusion-case)
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://coky-t.gitbook.io/owasp-ai-security-and-privacy-guide-ja/owasp-ai-sekyuritioyobipuraibashgaido/ai_security_overview.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.